Introduction
The application of personalized medicine for disease diagnosis and treatment is accelerating, enabling targeted therapies for various illnesses. The FDA has approximately 260 drugs with a label of pharmacogenomics, some of which include specific actions to be taken depending on biomarker information such as gene expression differences and chromosomal abnormalities. Personalized medicine is often called precision medicine or genomic medicine, but personalized medicine should be a more generalized term, because genomics is only one way to pre-determine the best medication for a specific patient with a history, symptoms and disease development that are unique to them. Using a variety of biomarkers, an algorithm weighing all these factors into a treatment decision should direct the physician to the best medicine for that specific patient, because although the symptoms experienced by that patient may seem similar to those reported by others, the cause or origin of a disease may be different. A simple example for how a different medication would be better in different cases presenting with similar symptoms is a viral versus a bacterial throat infection. Both diseases present with a sore throat accompanied by fever, but physicians know how to diagnose the best treatment for each of these cases, and the treatment is different.
When dealing with diseases that are more complex in nature, the diagnostic tools become more complex. Psychiatric disorders have been shown to be polygenic; usually the penetrance of a single variant is low and so is its added effect on the overall phenotype. Therefore, providing precision medication requires more sophisticated algorithms. We live in an era in which computational capabilities double every two years (
1); dealing with this reality, accompanied by the outburst of availability of genomic, neuroimaging and other new techniques such as cell reprogramming and gene editing, it is to be expected that the task of finding the most suitable medication will be based on diagnoses and predictions derived from all of these available techniques.
The prevalence of various psychiatric disorders among the population is estimated to be an astonishing number, about 30–40% (
2–
4). It is only quite recently, however, that we started realizing the complexity and heterogeneity of the genetics underlying these disorders (
5–
11). For example, genome-wide association studies (GWAS) analyses revealed a large number of single nucleotide polymorphisms (SNPs) with a significant association with disease but low penetrance in a diseased population. It may be that a certain amount of variation needs to accumulate or that these variations act as a network to cause the symptoms that we associate with these disorders. It is interesting to note that, in some psychiatric disorders such as autism, less than 3% of the cases are caused by a small number of rare de novo mutations with a high impact (
12,
13), such as Smith Magenis syndrome (
14) (where a deletion occurs on the short (p) arm of chromosome 17 at a p11.2), Rett syndrome (mutation in MECP2 gene) (
15) and fragile X syndrome (inherited or de novo mutations in FMR1 gene) (
16). While all share features typical of autism, the cause of each syndrome is very different, and each has been labelled as a sub-category.
By contrast to genetic heterogeneity in complex disease, there is also the other side of the coin: when the same (or similar) genes cause different disorders, pleiotropy. For example, disrupted in schizophrenia 1 (DISC1), neuregulin 1 (NRG1) and CACNA1C mutations and polymorphisms are known to be associated with schizophrenia, bipolar disorder and major depression (
17–
20). Another example is the gene dystrobrevin-binding protein 1 (DTNBP1), which has been implicated in schizophrenia, bipolar disorder and major depression (
21–
24). There are additional genes implicated in schizophrenia, bipolar disorder and autism spectrum disorder such as NRXN1, CACNA1C, CACNB2 and CNTNAP2 (
25–
27). It is possible that some genes are more vulnerable to environmental stress. It also could be that, in order for a phenotype to show, a network of genes acting together is needed; therefore, each gene by itself is not strongly selected against, and they can be well transmitted without loss of fitness in most cases but, with enough accumulation of mutational burden, disease will occur. The main conclusion when it comes to treatment selection is that the origin of each disorder is so complex that no single treatment is best for these disorders; the whole genetic, epigenetic and environmental background should be taken into account.
The diversity of available drugs today for psychiatric disorders alone shows the difficulty of finding the right treatment for the right patient. The mechanism by which these drugs act is usually not well understood. Each drug carries a long list of side effects, so when an ineffective drug is prescribed, not only is it a waste of time for the patient whose symptoms do not improve, but there are also the side effects that act on other systems, sometimes causing long-lasting and irreversible damage. For schizophrenia, for example, there are over 30 suggested drugs, including antipsychotics (
28,
29). While 30% of the patients will not respond to the drugs at all, about 30–40% will have a partial response and approximately 30% of the responders will relapse (
30). For bipolar disorder, lithium is currently considered the first-line treatment, but only 30% of bipolar disorder patients will fully respond to it (
31,
32). Other drugs used to treat bipolar disorder include mood stabilizers, antipsychotics, a combination of antidepressants and antipsychotics, and anti-anxiety medication (
33–
35). For major depression, around 30–50% of the patients have full remission of symptoms with treatment (
36–
38). The treatments include selective serotonin reuptake inhibitors (SSRIs), which are prescribed first (e.g. Prozac, Sertraline), norepinephrine–dopamine reuptake inhibitors such as bupropion, and older classes of antidepressants such as tricyclic antidepressants and monoamine oxidase inhibitors (
39). These antidepressants are sometimes combined with mood stabilizers such as lithium and valproic acid (
40). For autism spectrum disorder, drug treatment is used to reduce irritability and aggression. Two drugs have been approved for treatment in children, risperidone and aripiprazole; other drugs include clozapine, haloperidol and sertraline (
41). Yet other drugs are used to treat attention deficit hyperactivity disorder (ADHD) or sleep disturbance; SSRIs are sometimes used to treat anxiety or depression.
In this review, we summarize studies aiming to find predictive biomarkers for the drug that is the most suitable medication for patients with one of the following psychiatric disorders: bipolar disorder, schizophrenia, autism spectrum disorder and major depression. For each disorder we present previous associations and even prediction attempts of treatment outcome using clinical data, GWAS, neuroimaging and other techniques. Currently, the field of prediction of drug outcome is in its infancy, and much work needs to be done. Developing a good predictor will be extremely rewarding because the burden of these diseases on world finances is very large and, more importantly, finding the right drug for the patient will often allow patients to lead normal lives.
Discussion
The field of precision medicine for psychiatric disorders is in its initial phase. Accurate prediction attempts of treatment efficacy are rare. There are, however, quite a few studies showing associations and correlations of different biomarkers with a good outcome of drug treatment. The methods used include neuroimaging, electrophysiology, GWAS studies, behavioural studies, animal models, EEG, transcriptomics and others. Importantly, to accomplish the task of assigning the best drug to each patient, the studies that are most relevant are those that predict outcomes of specific drugs. To build precision medication tools, it is important to identify the features that will direct the clinician to the drug that is most suitable for a specific patient.
Building a large dataset requires the repository of data from thousands of people. Ethical questions such as who would have access to these data or tests required by insurance companies should be addressed (
137,
138). An important question that needs to be asked when getting a suggestion of treatment from a computer program is: what is the minimal accuracy that we should request before prescribing a patient with a drug? This is probably where the physician’s experience and knowledge would be useful. Medicine with adverse side effects should be given only if the error rate of the prediction is very low, and also then monitored closely. With medicine with fewer side effects, the accuracy requested from the algorithm can be relaxed. A good algorithm should also give multiple treatment options with a list of preferences.
Reviewing previous studies of associations between drug response and genomic and biological markers, a major downside that is very evident is the lack of replication. Work needs to be repeated, sometimes in a larger cohort, to make sure that these markers for drug response outcomes are reproducible. Despite the fact that a repeated study makes smaller headlines, it is our responsibility to check for reproducibility and robustness. Markers that were found to robustly associate with a good drug response can then be used for robust predictions.
A relatively large amount of work has been done in GWAS, with quite a few associations. The genomic revolution now allows for fast and cheap DNA sequencing, and may bring great promise to the prediction of optimal treatment (
figure 1). But are these predictions good enough, and do they have a high enough prediction power? The path from variants and SNPs to neuronal function is long and mainly unresolved. SNPs and variants work very well with the cell machinery, but can a computer program imitate the cell’s ability to know how these small changes to the DNA sequence would translate into amounts of RNA and proteins, and eventually a phenotype? A study that shows a response in the function of neurons (
89,
139) provides a lot of information that can be used when building a predictor, because scientists can now associate variants with drug response with a much higher likelihood, even if this variant is not seen in larger populations. It is therefore worthwhile to work backwards from functional assays such as electrophysiology to identify biomarkers that correlate with the functional measurements. Common genetic features that associate with these biomarkers can then be identified and used for predictions.
It is also important to note that different genomic changes may lead to similar results. In performing GWAS with a large number of patients, different genomic variants that converge to a similar phenotype may be lost in the analysis and appear insignificant. While each of these genomic changes may appear in a small population of the disease, they may all eventually cause similar phenotypes (different small genomic changes converging to the same phenotype). We hypothesize that RNA expression may be more closely and immediately associated with the final phenotype; therefore, looking at RNA expression or protein levels will give us much better clues as to how cell function will be altered by genomic changes. One problem is that we collect blood samples from the patients, not neurons, which is where the disease is expected to manifest. The use of induced pluripotent stem cells to study disease allows for differentiation followed by transcriptomics, but this is a long process. The question is whether any of these transcriptomic changes could be observed in blood cells. Epigenomics may give us the answer, because genes that are repressed may be in a more compact area of the chromatin. We believe that more transcriptomic and epigenomic studies should be performed to identify changes that play a role in the response to specific drugs to complement the large number of GWAS studies.
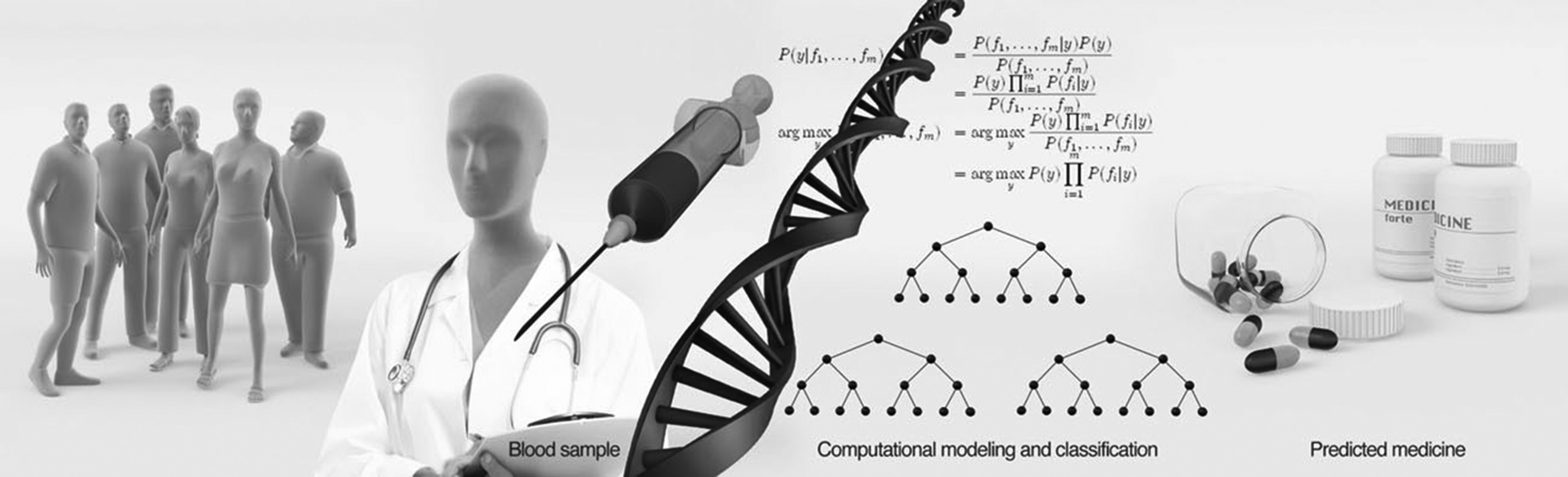
Importantly, when building classification algorithms, features extracted from different methods can be used together for prediction, and an algorithm does not need to be restricted to a specific method (
figure 2). The methods should be easy to implement in order to minimize the time needed to find the right treatment, and they should preferably not be very expensive. For example, sequencing of blood in combination with behavioural assessment is easy, and may provide a quick and relatively inexpensive prediction.
Figure 2 shows a general plot of an algorithm that would use features extracted from measurements using different methods for a prediction of the best drug. Much work needs to be put into finding these biomarkers that distinguish populations and make patients drug-responsive or non-responsive. The computational powerexists and so do the tools, and we need to use this opportunity to develop tools to help psychiatric patients and their families regain their quality of life.