The broad goal of supervised machine learning is optimized prediction, and it comprises algorithmic, data‐driven approaches that can handle large numbers of predictor variables (
4,
5). In particular, classification tree and random forest classifiers construct nonparametric algorithms that promote visual inspection of the data and an understanding of complicated interactions and nonlinear associations that are more difficult to identify and interpret using other methods (
4,
5,
6,
7) or that would not otherwise be detected (
8,
9,
10), allowing for identification of complex risk profiles without a priori hypotheses (
7).
Among military populations, most studies investigating predictors of mental health problems have focused on military—and particularly deployment—experiences rather than a full range of characteristics and stressors occurring both in and outside of military service. A broader picture of risk is needed, particularly for part‐time soldiers including the National Guard, who frequently transition between military and civilian life. Supervised machine learning methods can identify a wide array of factors associated with incident depression in this group.
Supervised learning has been used to predict psychiatric outcomes including suicide (
11,
12,
13), posttraumatic stress disorder (PTSD) (
14,
15), depression in very specific groups (e.g., elderly populations; (
16)), comorbid depression among patients with chronic physical conditions (
17), and depression treatment response in clinical samples (
18,
19,
20). To the best of our knowledge, classification trees and random forest have not yet been applied to predicting new‐onset (incident) depression in a military population.
Our objectives for this study were to (a) use a range of potentially predictive characteristics and experiences from across the life course to discern which variables and their interactions predict incident depression, using classification tree and random forest algorithms, and (b) assess predictive accuracies of these algorithms using cross‐validation, in a cohort of U.S. Army National Guard members.
DISCUSSION
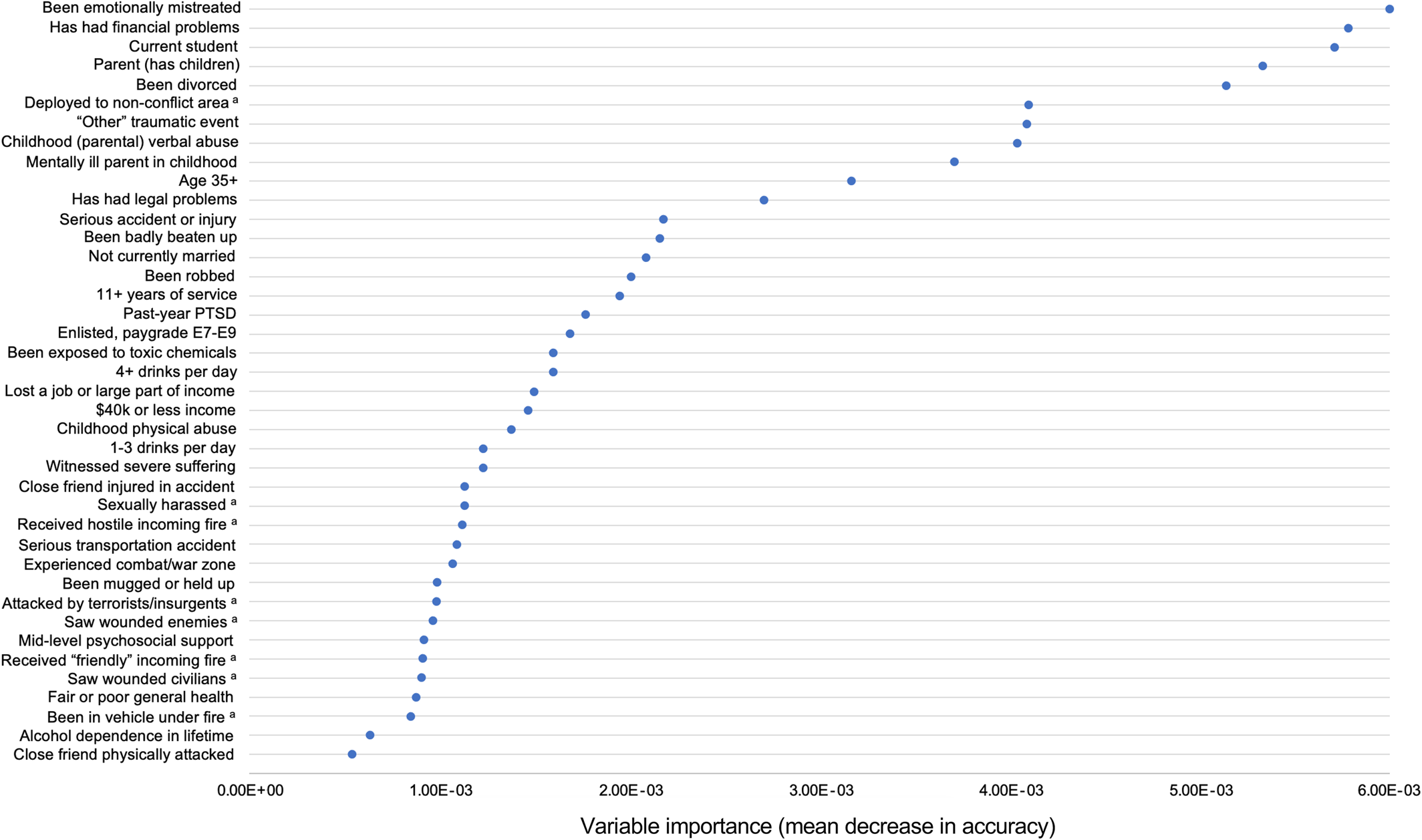
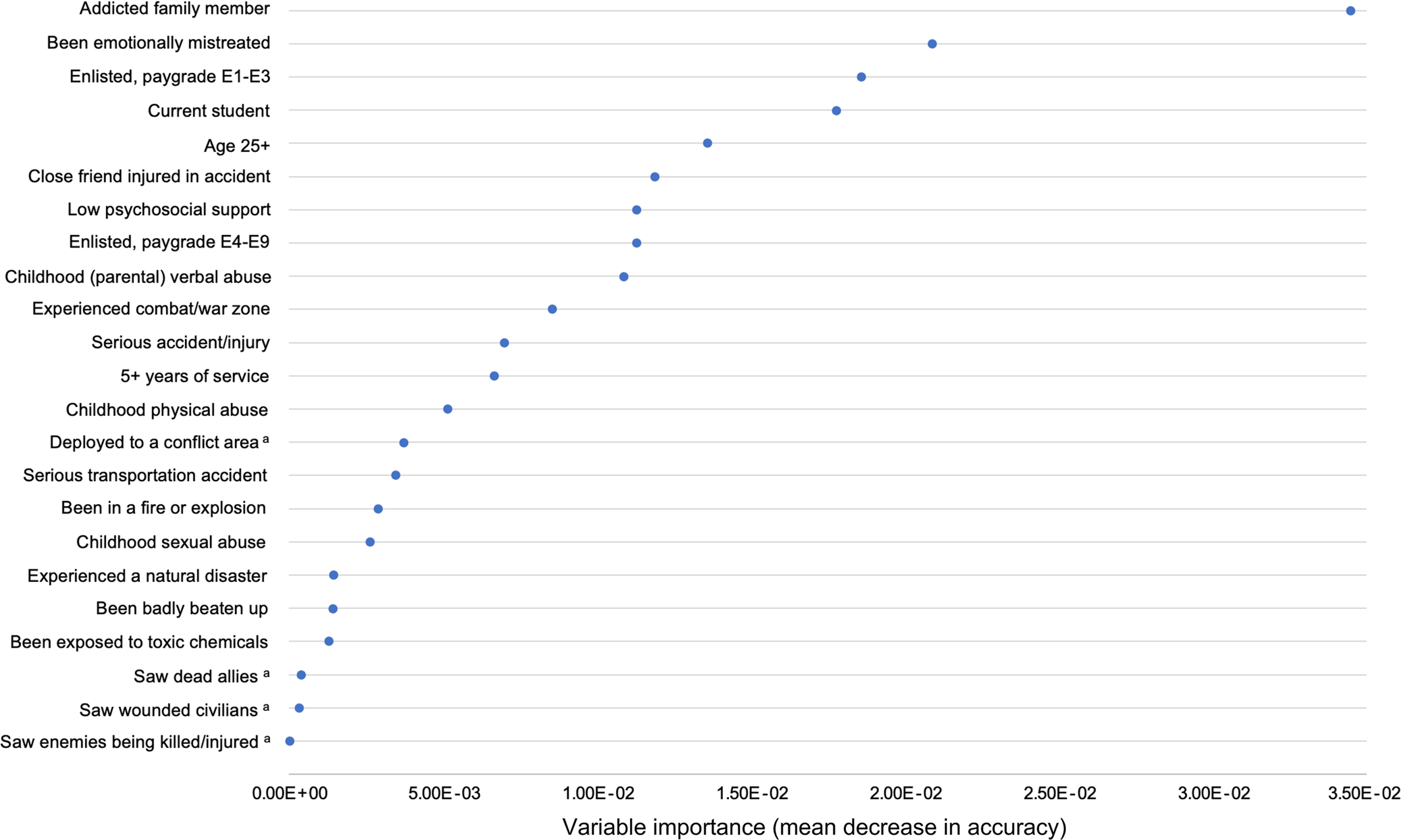
To the best of our knowledge, this study is the first to use classification trees and random forests to assess predictors of probable incident depression in a military sample. We found that, among both men and women, traumas and ACEs (particularly verbal abuse by a parent or guardian), stressors such as being emotionally mistreated, and demographics such as being a current student were predictive of incident depression during follow‐up. Military characteristics (e.g., paygrade), low psychosocial support, and hearing about traumas happening to friends or family (e.g., a friend was in a serious accident) appeared more predictive of depression for women than for men, whereas PTSD, deployment location, personally experienced traumas (including combat‐related experiences), and financial problems appeared more predictive among men compared to women.
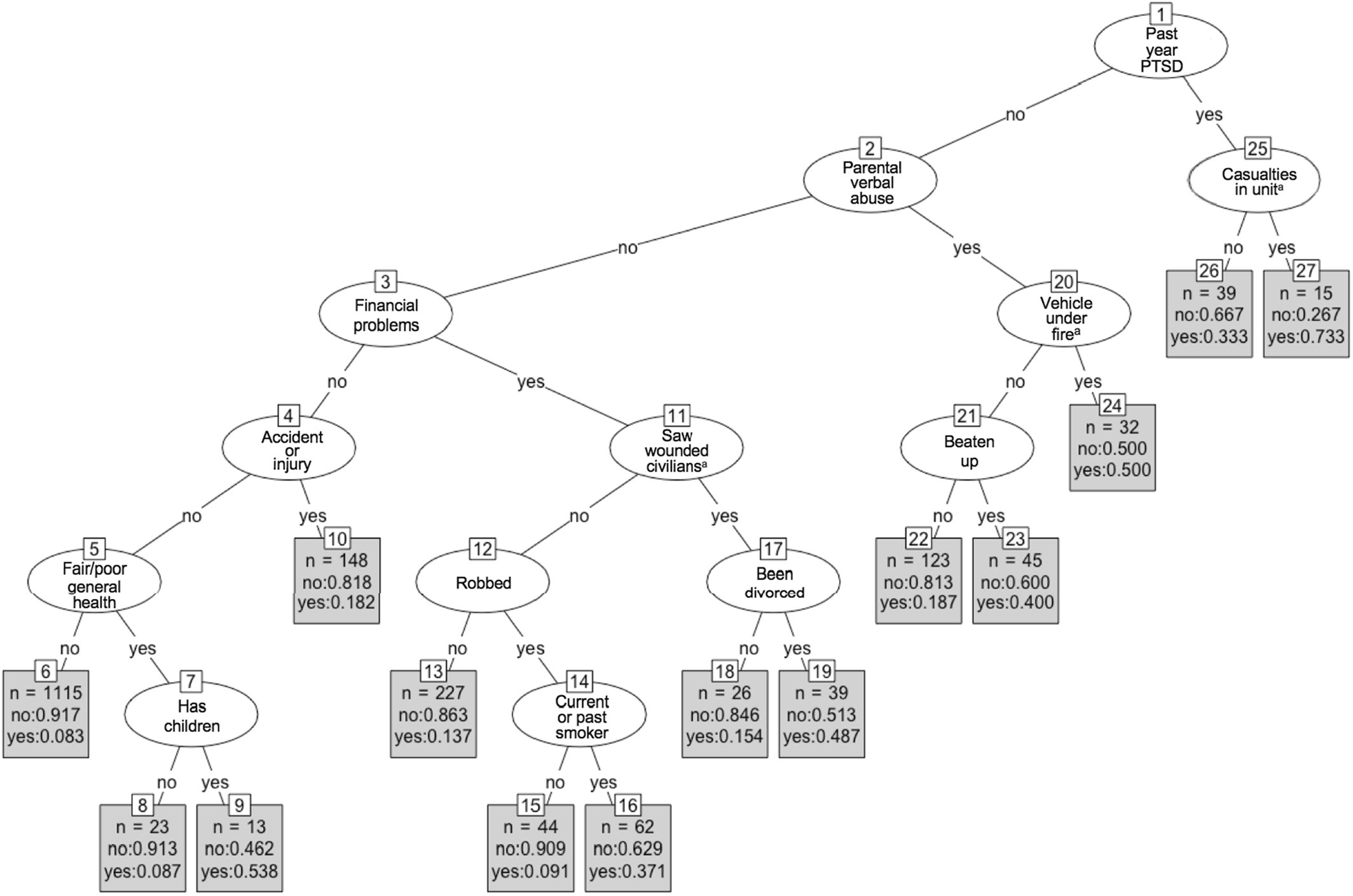
Among men, recent deployment to a nonconflict area was predictive of depression, compared to being deployed to either a conflict area (Iraq or Afghanistan) or never having been deployed. This may be due to stressful and unexpected domestic deployments to areas affected by natural disasters—which have been increasing in recent years—or to areas of civil unrest after riots or massive protests, which can involve National Guard deployment. These types of domestic deployment may be more distressing for soldiers than combat deployments overseas, because they can involve confronting fellow citizens (e.g., at protests that become violent) or witnessing citizens suffer (in natural disaster contexts). This finding should be replicated, but it could indicate that additional resiliency training may be warranted for these unique deployment experiences. We were unable to compare incidence of depression by exact location or type of recent deployments, given small cells and lack of detailed questions on the surveys.
Past‐year PTSD was the most predictive variable for incident depression among men in the single tree (and moderately predictive in the random forest, suggesting there may have been some overfitting in the single tree). This finding is broadly consistent with both with the only other study to use random forests to predict incident depression in a population‐based sample (
31) and with many non‐machine learning studies that have consistently found comorbidity between PTSD and depression (
32,
33,
34,
35). The combination of having both past‐year PTSD and reporting a unit casualty during the most recent deployment was particularly predictive of depression among men in the classification tree, for which the incidence of depression was 73.3%, or five times larger than the overall incidence of depression among men in this sample.
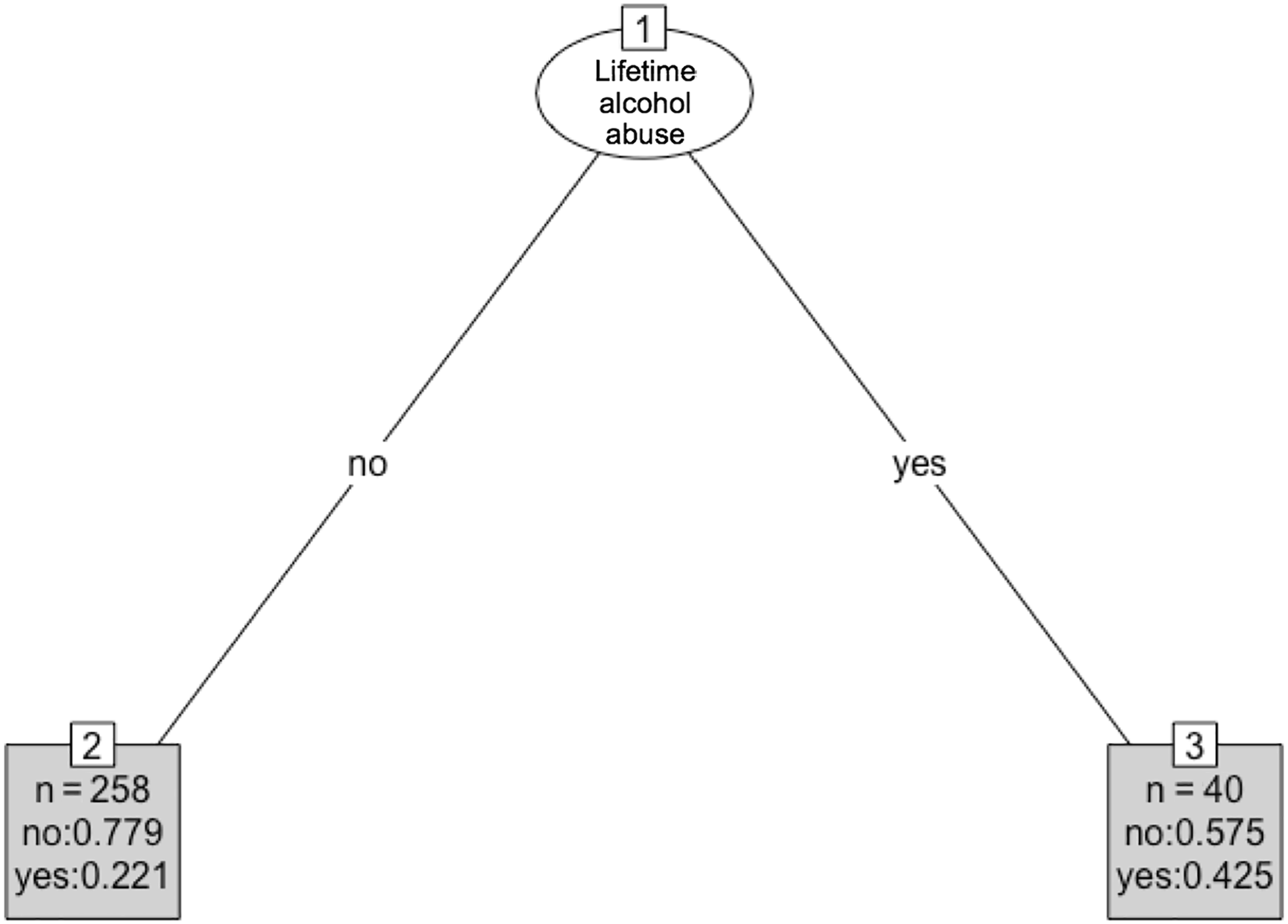
Among women in our study, PTSD was not predictive of incident depression, but lifetime PTSD status was included in the algorithm instead of past‐year status, given the small number of women with PTSD in the past year in an already‐small sample of women. This may be the reason why PTSD was not selected among women as being highly predictive, since history of PTSD may have occurred many years before onset of depression, and thus not as clinically or statistically relevant.
Our findings that ACEs and more recent traumas and stressors were predictive of incident depression (for both men and women) is also consistent with a prior machine learning study (
31) as well as many non‐machine learning studies that have modeled incident or prevalent depression with similar types of events as exposures or predictors (
36,
37,
38). Traumas and stressors such as being mistreated have long been known to associate with depression outcomes (
39,
40,
41,
42), particularly when they occur during childhood, while brain is still developing (
42,
43).
Finally, our findings on financial problems, being a student, being of lower paygrade, and having children may all be related to financial stress, debt, and concern about being able to provide for one's family, which have been found in non‐machine learning contexts to be associated with depression (
44,
45,
46,
47).
Based on 10‐fold cross‐validation, our random forest algorithms were moderately accurate overall (73% accuracy for men and 68% for women). These values are in line with other studies predicting depression outcomes; Kautzky and colleagues (
18), who used random forests to predict treatment‐resistant depression, found accuracies of 68%–75%. Similarly, Jin and colleagues (
17), who used four different prediction methods including random forests to model depression (also measured using the PHQ‐9) among patients with diabetes, found comparable levels of accuracy (approximately 73%).
Limitations of our study include the use of baseline information alone to predict incident depression over follow‐up. It follows that we lack (a) time‐varying information assessed on the follow‐up surveys that could be temporally closer to onset of depression compared to baseline variables, and (b) information on exact timing of prior events and experiences, as the baseline surveys primarily assessed events that occurred at some point in the past, without asking detailed information on timing (with the exception of other mental disorders). However, using only baseline predictors in this study established temporality between our predictors and outcome—a crucial aspect of valid prediction.
Another limitation is our use of the PHQ‐9 for measuring depression. Although the PHQ‐9 has been validated against a gold standard depression measure within this cohort as well as in many other populations (
24,
25), it is primarily a screening tool and was not designed as a diagnostic test. Thus, it is possible that there are individuals in this study with incorrectly classified depression status, which could have affected which variables were chosen as being predictive. Future studies should aim to replicate these results using diagnostic measures of depression.
Finally, we used a complete case analysis for the cross‐validated random forests. Missing data in this study stem primarily from the fact that ACEs were not asked on the baseline survey for the first (and largest) cohort of participants. For those individuals, the ACEs were assessed in the second wave of the study, at which not all respondents were present. A smaller portion of missing data came from responses of “don't know” or declining to answer questions such as income. As this is a prediction study and thus we are not aiming to isolate and measure the effect of any particular variable on depression, missing data are not as problematic of an issue as in an explanatory study. Generally, missing data among predictors in prediction modeling are thought to only create bias if missingness is related to the outcome variable (
9,
48). We have no reason to believe that this is the case in our study, as all predictors are from the baseline interview, at which time the outcome had not yet occurred (with the exception of the four ACEs assessed at Wave 2 for the primary cohort, which were missing by design, not by refusal to answer).
Despite these limitations, these results may help inform potential screening interventions for depression in this population. Algorithms represent concrete ways officials might identify characteristics associated with high risk of developing outcomes, regardless of underlying causal relationships; this might be especially useful in a military setting given that military personnel are feasible to monitor. For example, the REACH Vet algorithm, built by researchers using machine learning, helped the U.S. Department of Veterans' Affairs to identify veterans at high risk for suicide (
49,
50), as part of a crucial undertaking at a time when suicides among military personnel have been increasing.
Future analytic work that aims to predict depression—preferably using larger samples and more specifically timed predictors than we were able to utilize in this study—should aim to replicate our findings and further refine interactions between variables identified here. Machine learning might also be used to predict particular subtypes of depression, given that the overall disorder is heterogeneous and takes on different forms in different individuals; this may improve prediction accuracy. Predictive accuracies of the algorithms could also be compared with individual‐level prediction using more traditional types of regressions, or using other types of machine learning algorithms, including ensemble methods such as Super Learner which average across different types of algorithms. Finally, broader environmental and context‐level variables—like unit‐level characteristics in a military study or residential neighborhood‐level characteristics in a general population survey—may be important for prediction of individual incident depression (
51,
52), and should be included as predictors in future studies, where sampling designs allow.