Depression is an illness with staggering personal, clinical, and societal costs and high prevalence in primary care settings (
1,
2,
3,
4,
5 ). The heterogeneity of patients with depression in primary care is a major issue affecting how policy makers, clinicians, and researchers plan for and evaluate depression treatment. Depression treatment improvement studies usually address heterogeneity through case mix adjustment of analyses, using a variable mixture of demographic characteristics and comorbidities (
6,
7,
8 ). This approach, however, cannot produce valid estimates of the impact of the case mix adjustors either individually or as a group on outcomes.
In contrast, prognostic or risk stratification indices identify a set of characteristics that produce an estimate of the relative probability that an individual or group will experience a poor outcome at a later time (
9 ). Such indices, if systematically developed and validated, can minimize threats to research validity resulting from unmeasured case mix and standardize comparisons across different studies (
10 ). Prognostic indices are also clinically useful for assessing patient needs (
11,
12,
13,
14 ) and predicting hospital charges (
15 ) and as the basis for developing clinical rules or heuristics (
16,
17 ). This article reports the development and validation of a Depression Prognosis Index (DPI) for predicting likelihood of recovery from depression over a six-month period among primary care patients.
Prognostic indices are commonly used in medical studies (
9,
15,
18,
19,
20,
21,
22,
23 ) as well as in medical settings such as intensive care units (
19 ). These indices are less commonly used in mental health care or research. Efforts to increase the effectiveness of mental health care for diverse populations and settings, however, will demand better prognostication. For example, individualizing care for subpopulations on the basis of important prognostic indicators holds promise for improving cost-effectiveness (
24 ) and is consistent with stepped-care models of collaboration between mental health and primary care (
6 ). On a practical level, analysis of data gathered from heterogeneous settings typically involves multilevel models (
8,
25,
26 ) with patients clustered within clinicians, practices, and organizations. The inclusion of a single valid prognostic value in analyses, instead of a long list of separate adjustors, can improve the stability and performance of regression models while improving adjustment for case mix (
9 ).
Depression prognosis is affected by factors beyond the severity of depression symptoms, such as those identified by
DSM-IV diagnostic criteria. A growing literature on treatment-resistant depression, for example, identifies additional factors that affect failure to recover despite appropriate treatment (
27,
28 ). Still other patient characteristics affect whether patients successfully access and complete treatment—the main quality deficit in primary care for depression (
29 ). Our analyses addressed both characteristics related to treatment resistance and characteristics related to failure to initiate or complete treatment.
To carry out our analyses, we used secondary data from a representative sample of 1,471 primary care patients with depression who were cared for by 108 geographically and structurally diverse primary care practices. We systematically identified patient characteristics that best predicted depression outcomes six months after detection of major depression from each of five domains: physical, mental, and social health status; demographic characteristics; and treatment history.
This study extends previous research findings by developing and rigorously validating a depression prognosis measure. Validated measures of this kind are appropriate for immediate use but should be used judiciously; most commonly used prognostic indices have continued to be refined over a decade or more (
18 ). On the basis of previous research (
9 ), demonstrating that a prognostic index accounts for at least 20% of the variance in outcomes in a validation sample (that is, has an R
2 greater than .20) is a reasonable standard for considering an index to be potentially useful and worthy of continued development.
Methods
A more detailed description of methodologic and analytic procedures is available in monograph form (
30 ). All study procedures were approved by institutional review boards at RAND as well as at participating organizations.
Sample and data
The DPI is based on data from the Quality Improvement in Depression study (QID), a group of four depression care improvement studies that collected uniform baseline data in 1996–1997 from 1,471 representative patients with major depression from 108 practices in 11 states (
31 ). QID used encouragement methods to help practices adopt strategies for increasing the proportion of their patients who received guideline-concordant depression care (
31 ).
Each study enrolled a representative cross-section of adult patients with current major depression by approaching consecutive patients attending primary care appointments and screening them for eligibility by using items from the World Health Organization's 12-month Composite International Diagnostic Interview (CIDI) (
32 ). Patients were excluded if they had an acute life-threatening condition or cognitive impairment; indicated that they did not intend to receive care in the clinic on a ongoing basis; had no access to a telephone; were currently pregnant, breastfeeding, or less than three months postpartum; or screened positive for current bereavement, lifetime mania, or severe current alcohol abuse. All patients with major depression or dysthymia based on the full CIDI were enrolled (1,471 patients). In addition, two of the four studies enrolled 321 additional patients meeting criteria for subthreshold depression.
All four projects then collected self-reported data for enrolled patients at baseline and six months later either by telephone (Hopkins Quality Improvement for Depression, the Mental Health Awareness Project, and the Quality Enhancement by Strategic Teaming Project) or by self-report mail survey with telephone follow-up as needed (Partners in Care). Detailed methods are published elsewhere (
31 ) and available upon request from the authors.
Outcome measures
Our primary outcome measure was depression symptom severity at the six-month follow-up. It was measured by the Center for Epidemiologic Studies Depression Scale to which slight modifications were made to more closely approximate
DSM-IV criteria (
33,
34 ) (mCESD). We also measured the presence or absence of persistent depression at six months (
35 ). This dichotomous variable indicates a likely diagnosis of current major depression on the basis of whether the patient scored in the depressed range on each of three measures: the mCESD, the mental health composite score of the 12-item Short Form Health Survey (MCS-12) (
36 ), and stem items from the World Health Organization's CIDI assessing current "probable depression" (
32 ). On the MCS-12 a score of more than 1 standard deviation below the general population mean of 50 falls in the depressed range. For the mCESD the depressed range was above a cutoff point of 20, which is equivalent to the standard cutoff point of 16 on the original CESD (
37 ).
Predictors of poor prognosis
Our database included a majority of factors previously identified or theoretically postulated as predictors of depression outcomes. We conceptualized prognosis as being based on physical, mental, and social health status, demographic characteristics, and treatment history and identified these as domains of poor prognosis for our analyses. Among physical health factors, prior evidence identified a larger number of comorbid general medical problems as a negative prognostic factor (
38,
39,
40 ). Among mental health factors, severe initial depression symptoms, psychiatric comorbidities, and a history of depression treatment have been associated with poor prognosis (
41,
42 ). Among social health factors, low social functioning and support worsen prognosis, as do the demographic factors of being older and male, having low educational attainment, or being unemployed or a member of a racial or ethnic minority group (
40,
43,
44,
45,
46,
47,
48 ). Below are listed key variables included in our analyses from each domain. A complete list of candidate variables is available elsewhere (
30 ).
Physical health. Physical health was measured by severity of symptoms common among people with depression. A scale indicating degree of interference with usual activities from five common physical health complaints—nausea or upset stomach, daytime sleepiness, dizziness or lightheadedness, difficulty urinating, and sexual dysfunction—was used. Measures of physical functioning were based on the 36-item Short Form Health Survey (SF-36) (
49,
50 ). The number of chronic general medical problems was documented (
35 ), as was the level of pain (
49,
50 ).
Mental health. Current and past depression symptoms and history were obtained from the mCESD (
34 ) and CIDI (
32 ). Also documented were depression symptoms lasting longer than two years, a history of suicide attempts, anxiety, panic, irritability or anger, and the quantity and frequency of alcohol consumption (
51 ).
Social health. The SF-36 was used to measure work status and functioning and limitations in household activities (
49,
52 ). Social support was measured with a nine-item subset from the Medical Outcomes Study Social Support Survey (
53 ). Participants were asked whether they perceived that health interfered with social activities. They were also asked about negative life events (
54 ).
Demographic characteristics. Information was obtained about income, education, ethnicity, and time and miles to access primary health care, mental health care, a pharmacy, and a hospital.
Past process of physical and mental health care. Data were collected on use of antidepressant medications, mental health counseling, and medical care before study enrollment (
55,
56,
57 ).
Analysis
Analyses aimed to identify a parsimonious, clinically meaningful index comprising a set of predictive variables linked to regression weights that could be applied to measure prognosis for any patient population with minimal if any deterioration in prediction. We used the sample of 1,471 patients with major depression to develop the index. We used weighting and multiple imputation to maximize the index's accuracy for difficult-to-survey subpopulations that tend to generate more missing data than others, even when overall response rates are high (such as members of minority groups). We used a systematic stepwise clinical model-driven variable reduction process to reduce the likelihood that variable selection would be influenced by unpredictable effects of collinearity. Finally, we used a statistically robust split-sample validation approach (
58 ) to maximize the generalizability of our findings.
Data reduction. Data were analyzed with SAS (
59 ). We randomly selected one-third of study patients as a test or training sample for development of preliminary prognostic models (
58 ). Using SAS PROC REG, we first selected all variables within each poor-prognosis domain (for example, social health) that predicted six-month depression symptom severity (mCESD at p<.20). We entered selected variables into "mini" stepwise regressions (SAS PROC REG, option stepwise) predicting symptom severity within each domain. We entered the final candidate variables that were significant at p<.15 in the miniregressions into a combined stepwise regression and retained all predictors significant at p<.05. We then eliminated variables with the lowest partial R
2 values (that is, <.012).
Validation and final scoring. We cross-validated the preliminary, or test sample, DPI on the remaining two-thirds of the sample by using the regression coefficients from the two preliminary models as weights and assessing their predictive validity when applied to the remaining two-thirds. We also tested the validity of the model in subgroups: separate samples from each of the four QID studies, only patients who received the study intervention, only patients who did not receive the study intervention, and only patients who began their depression treatment episode at baseline (that is, they had not had any treatment in the previous six months). In these and subsequent validation analyses, we used the squared multiple correlation between the predicted values and the observed values in the validation sample as the cross-validation R
2 . We developed the DPI final scoring weights by pooling the developmental and validation samples, as suggested by Kleinbaum and colleagues (
58 ), and by calculating regression coefficients for the DPI variables across the pooled sample.
To assess whether theoretically important variables had been eliminated by chance during our scale development, we tested whether variables previously identified as prognostic in the literature but eliminated from the DPI during our testing process added to model R 2 values. Tested variables included the SF-36 mental and physical health composite scores; suicide attempt, plan, or ideation; probable prior depression; recent panic attack; quantity and frequency of alcohol consumption; work status; and number of chronic diseases.
To test the influence of study interventions on the composition of the DPI, we redeveloped index weights from unstandardized regression coefficients using the control group alone as our sample. We evaluated how these new predicted scores correlated with scores generated by the existing DPI.
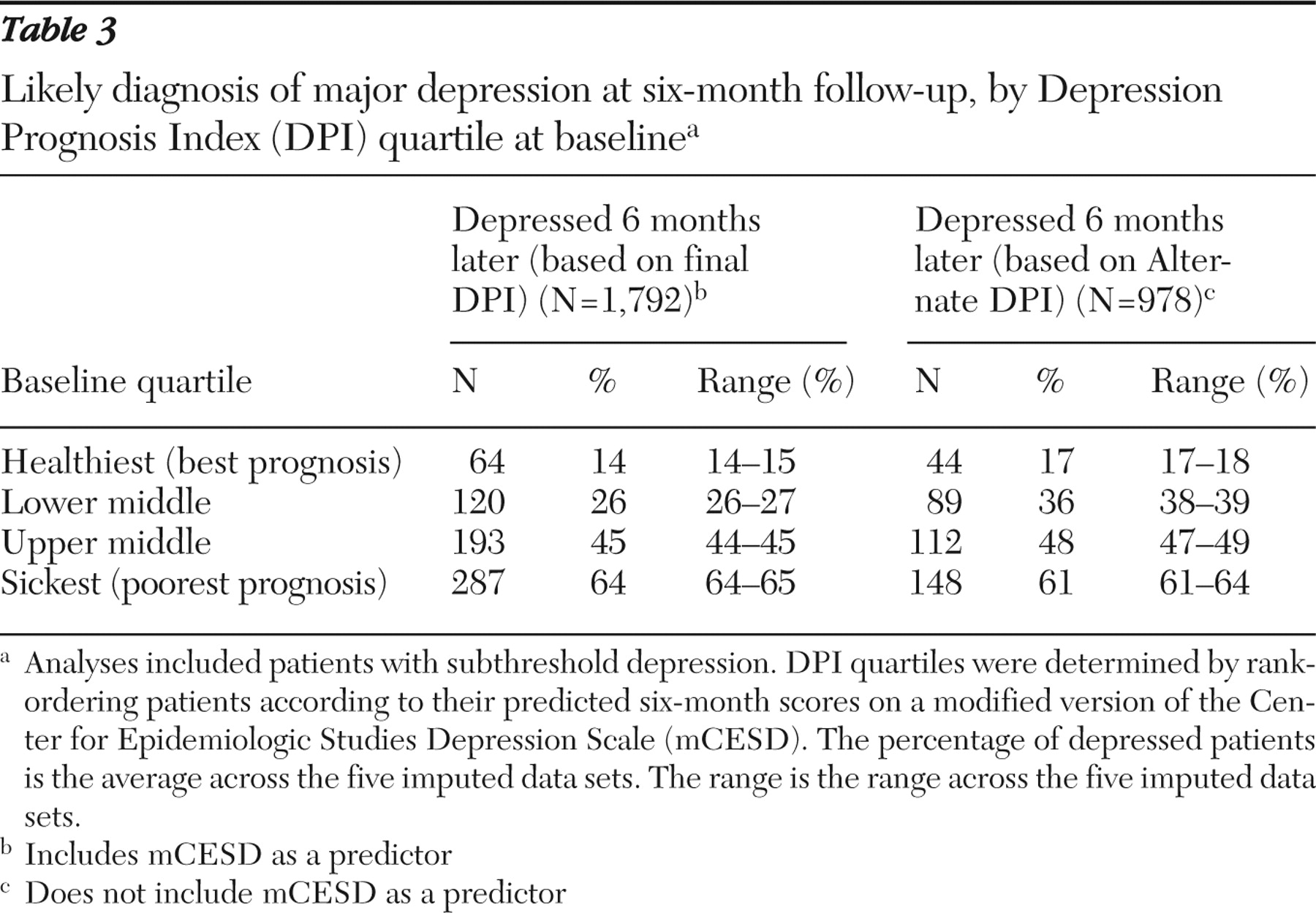
Finally, we tested the clinical meaning of the DPI by rank-ordering patients according to their baseline DPI scores. We grouped them into quartiles from best to worst prognosis. We then calculated the percentage of patients within each quartile who actually experienced persistent major depression six months later. To maximize patient diversity for testing, we added the 321 patients with subthreshold depression for a total sample of 1,792.
Missing data. Data were weighted for the probability of enrollment and attrition at each step of enrollment and each survey wave by using SAS. We used multiple imputation (that is, we generated five randomly imputed data sets) to generate values for some missing items (
59,
60,
61,
62 ) using an extended hot deck technique that modifies the predictive mean matching method. The final analysis results are summarized across the five imputed data sets by using multiple imputation inference methods: the point estimates are averaged across the five imputed data sets, and the standard errors within the imputed data sets are combined with the variation of the point estimates across the five imputed data sets to form standard errors that reflect both within-imputation variability and between-imputation variability (
61,
63 ). We carried out all initial analyses on the first data set and retested in each of the four remaining data sets. Final results were averaged across the imputed data sets, correcting for clustering at the provider practice level (
58,
64 ).
Alternate DPI. To test the extent to which variable selection was conditioned by inclusion of our baseline depression symptom severity scale (mCESD), we conducted all of the development and validation steps above excluding this variable from the data set. We labeled the resulting index the Alternate DPI. Because initial runs showed the importance of anxiety variables, and only three of the four QID surveys fully matched on anxiety items, we calculated the final Alternate DPI for the 828 patients with major depression from the three studies with common anxiety variables and tested it for predicting persistent depression among the 978 patients with major or subthreshold depression from these studies.
Results
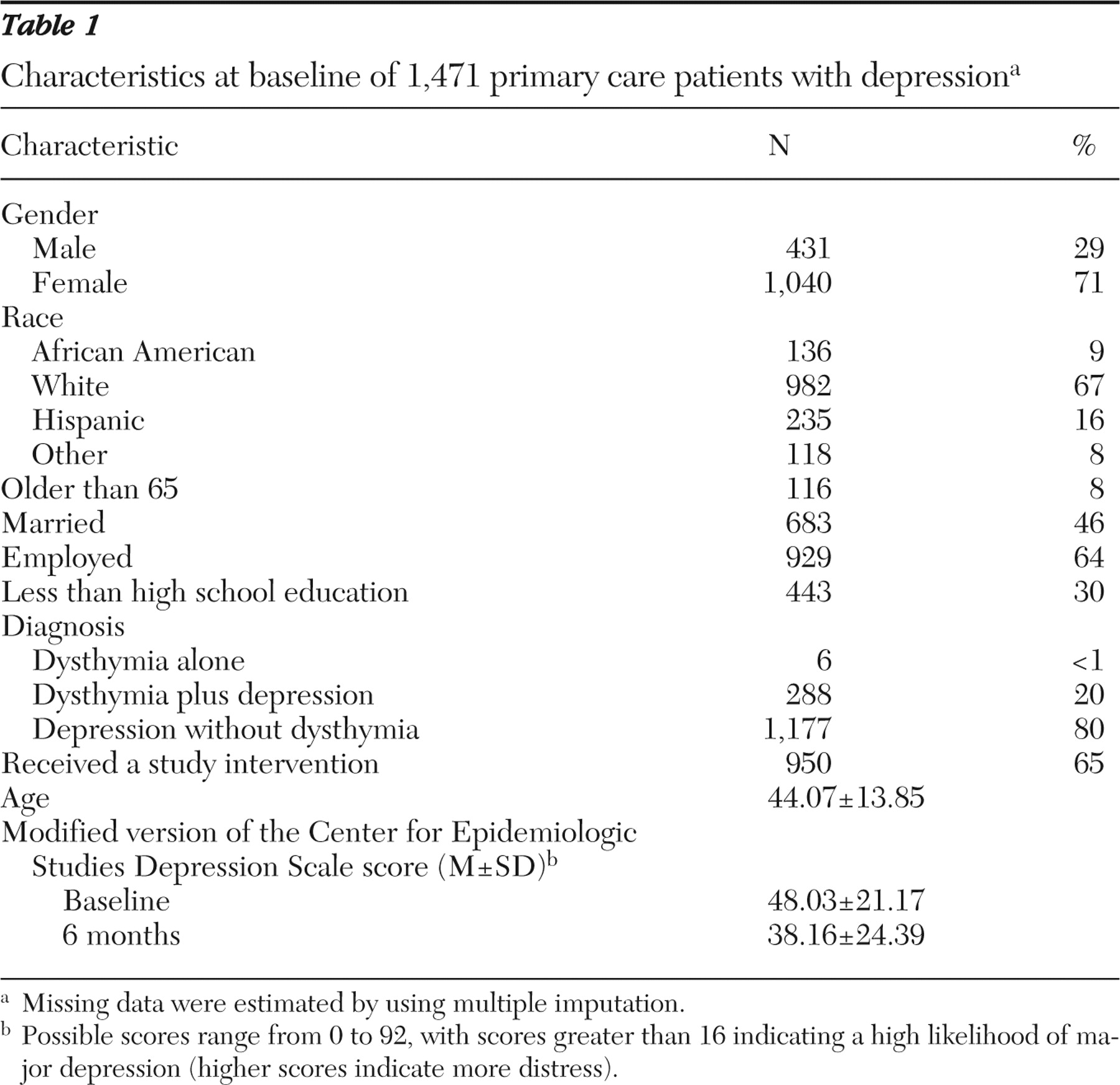
Baseline characteristics of our patient population (N=1,471) are shown in
Table 1 . Men accounted for about one-third of the sample (29%). A third were members of a minority group (33%). Thirty percent had less than a high school education, and 36% were unemployed. Eight percent were over 65 years old.
Univariate analyses within our five domains (for example, social health) conducted using our test sample yielded 55 variables that were assessed at baseline and significantly associated (p<.02) with depressive symptoms as measured by the mCESD six months later. In multivariate analyses that combined the significant variables from each domain, 24 variables remained independently predictive at a p value of less than .15, generating a model R 2 of .40. After variables (anger or irritability, time to the nearest hospital, and number of physical symptoms common among people with depression) that contributed minimal partial R 2 values (less than .012) were eliminated, the total R 2 for the final DPI was .33 with the test sample. The average R 2 on the validation sample (two-thirds of the sample) was .26 for both the final DPI and Alternate DPI across the five imputed data sets.
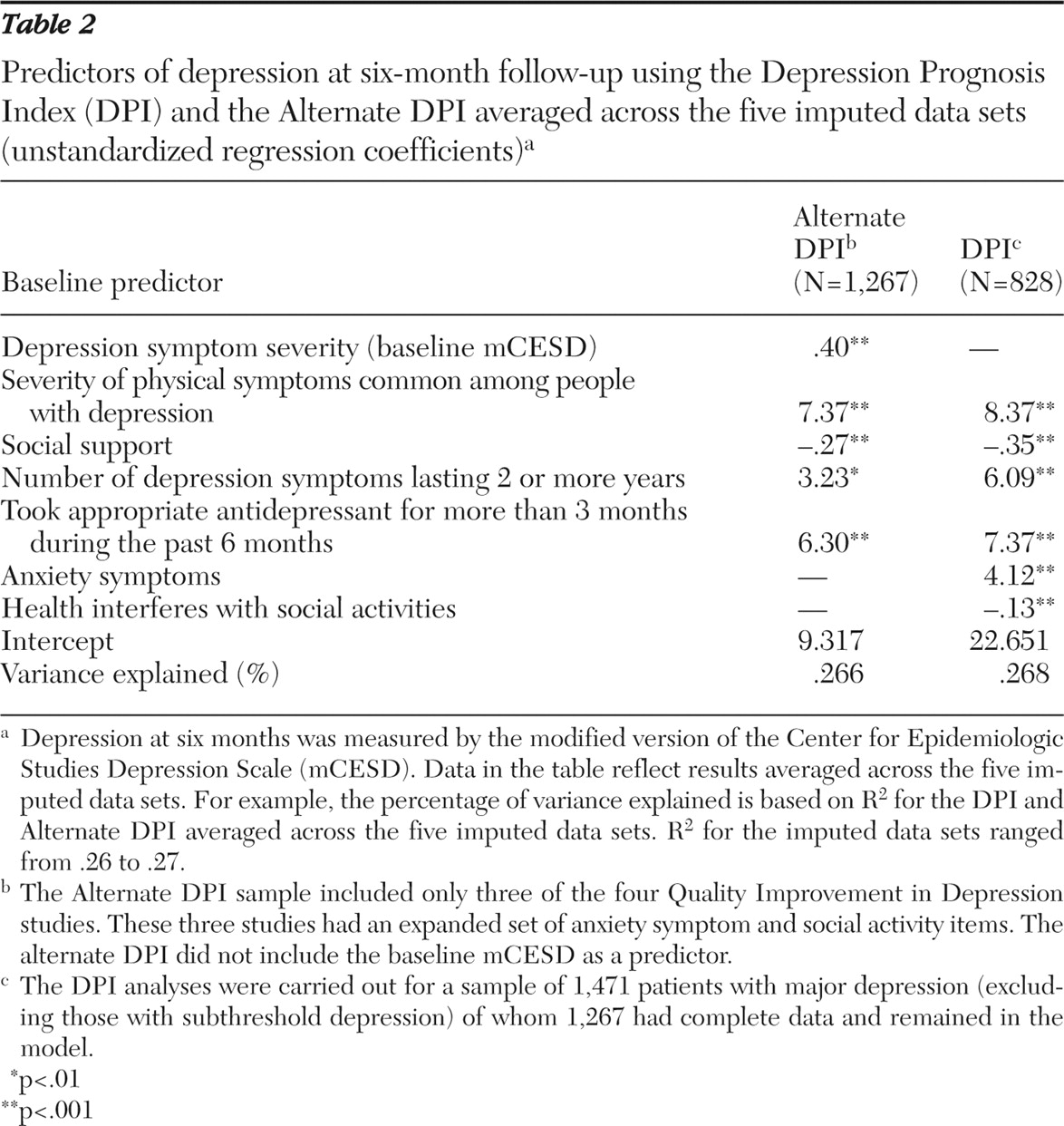
Final validation R
2 values for the DPI and Alternate DPI were all above our standard of greater than 20% for considering the index to be potentially useful, ranging from .26 to .27 across the five imputed data sets and averaging .27 (
Table 2 ).
Table 2 also displays the coefficients for the DPI and Alternate DPI predictor variables. The sample includes all 1,471 patients with major depression (DPI) and all 828 patients with major depression from the three studies that administered the same anxiety battery (Alternate DPI). Final DPI predictors were score on the mCESD, severity of physical symptoms common among people with depression, social support, number of depression symptoms lasting two or more years, and receipt of an appropriate antidepressant for three or more months during the past six months. Final Alternate DPI predictors included all DPI predictors (other than the excluded mCESD) as well as anxiety symptom severity and the perception that health interfered with social activities.
The R 2 values for nine additional validation analyses (for example, for the control group alone, experimental group alone, each study separately, excluding patients with very low depression severity, and excluding patients who initiated treatment after baseline) ranged from .21 to .42, with an average of .28. Validation results for the Alternate DPI (with the mCESD excluded as a predictor) were similar.
Adding variables to the DPI that had been eliminated during model development but were important predictors in the literature did not add significantly to the DPI's predictive power. Recalculating a predictive index using the control group alone showed correlations ranging from .94 to .95 across imputed data sets between the control group-derived index and the DPI.
Table 3 shows the percentage of patients within each DPI and Alternate DPI quartile who had persistent depression at the six-month follow-up. Fourteen percent to 15% of patients (across imputed data sets) identified by the DPI as having the best prognosis at baseline (with DPI scores in the best-prognosis quartile of the study population) had a likely diagnosis of persistent major depression six months later. This contrasts with 64%–65% of patients identified by the DPI as being in the worst-prognosis quartile. The logistic regression equations used in these analyses passed the Hosmer and Lemeshow (
65 ) goodness-of-fit test. Unimputed data gave virtually identical results.
Discussion
We tested the feasibility and accuracy of predicting recovery from depression over a six-month period using a prognostic indicator based on patient self-reported characteristics at baseline. We found that levels of prediction yielded by our indicator were in the range considered useful in similar analyses for general medical problems such as congestive heart failure (
9 ). Had we found no reliable prediction, considering the thoroughness with which our underlying set of variables represented previous research on characteristics associated with worse depression outcomes, we would have concluded that further development and validation of depression outcomes prediction tools based on current knowledge was unlikely to be fruitful. Instead, our findings indicate that the DPI achieved a useful level of prediction and that further research on depression prognostic indices is warranted.
Our findings are conservative both in terms of the diversity and representativeness of the sample we analyzed and in terms of the cross-validation strategy we used to gauge our final prediction levels. In an era of increasing attention to the benefits of tailoring care based on individual characteristics (
24,
66 ), prognostic measures are likely to increase in importance in both clinical and research settings. Research methodologists recommend inclusion of prognostic indices in treatment studies as a standard practice for reducing effects of unobserved sickness bias (
10 ), and clinical settings have successfully used such indices as the basis for shorter decision tools (
16 ), among other uses. Clinical managers can benefit from knowing who is at risk (
15,
19,
66 ), and clinical intervention developers can develop strategies for achieving better results among difficult-to-treat groups (
24 ).
Medical research on outcome prediction tools began two decades ago. The best known of these indices yielded levels of prediction within the general range we found for the DPI reported in this article. The Charlson Index (
21 ), used for predicting death resulting from comorbid conditions, is extensively used in research (
18 ) and has been validated for either medical record review or patient self-report (
67,
68 ). The Charlson Index classified patients into four groups with one-year mortality rates ranging from 12% to 85% on the basis of an initial development sample and from 8% to 59% in a validation sample. A widely used pneumonia prognostic index categorized patients into prognostic groups with mortality rates that ranged from 1% for the healthiest group to 37% for the sickest group (
12 ). MedisGroups, a commercial prediction instrument, produced R
2 values ranging from .09 to .33 across six conditions when added to diagnosis-related group class for predicting hospital charges (
15 ) but only .01 to .16 for predicting death at 30 days after admission (
69 ). The authors considered the latter R
2 values for predicting death to be "modestly predictive." The R
2 for the APACHE III prediction instrument, which uses prospectively gathered laboratory values, history, and clinical examination findings to predict risk of death in the hospital on the basis of admission values, was .41 in a validation sample, considered an outstanding level of prediction (
19 ).
Studies such as those described above show decreases in predictive ability between development samples and validation samples (
69,
70,
71 ). In our study, the R
2 of .40 in our development sample dropped to an R
2 of .27 in our validation sample. The final R
2, however, should remain stable in new populations. We expect stability also because of the diversity and representativeness of our patient and practice samples (
31 ). The 108 practices in the sample were not only geographically dispersed but represented a variety of practice models, including staff model managed care, network model managed care, and small independent family practices. The practices also varied in quality of care for depression, in part because of the experimental interventions experienced by some of them. However, the index performed as well in the experimental and in the usual care group, and the final DPI scoring weights remained virtually identical when rederived through analysis of the control group alone.
Because we systematically identified variables within clinically important domains, minimizing collinearity effects, our results are meaningful in identifying clinically important prognostic factors. For example, in our sample, social support, the presence of a greater number of common physical symptoms, and major depression at sample entry despite three or more months of antidepressant treatment were more important in determining depression outcomes than were other commonly cited factors, such as race or ethnicity, socioeconomic background, age, chronic disease load, or suicidality.
We expected that depression symptom severity at baseline, as represented by the baseline mCESD, would be a strong predictor of depression symptom severity six months later. Interestingly, we found that the Alternate DPI and the DPI had equivalent predictive power (R 2 =.27). Alternate DPI calculations exchanged baseline mCESD for a measure of anxiety and a measure of the degree to which health interferes with social activities and retained all other DPI variables.
Our study has limitations. Causality cannot be tested with our observational design. Although our sample was diverse, it included only patients with access to primary care. Also, although we identified only a few factors as important to prediction, the full index is lengthy, including about 60 individual items contributing to four to six validated scales. Some variables identified as outcome predictors in the literature were missing from our database—in particular, smoking, exercise levels, and symptoms of posttraumatic stress disorder. The QID studies used few exclusion criteria; however, the exclusion of patients with pregnancy or very heavy drinking (greater than six drinks a day) should be noted. Researchers who collect data for calculating the DPI can include additional predictors along with the DPI in regression models and test for changes in results. Additional research will be required, however, to learn which additional variables warrant inclusion in future depression prediction indices.
Conclusions
Our analyses demonstrate the validity of the DPI and provide a basis for future research on and development of depression prognostic indices. Our results also challenge clinicians and researchers to learn more about the effects, reversibility, and mechanisms of action of clinical variables, such as social support and physical symptoms, included in the DPI. Final DPI variables predicted outcomes better than did ethnicity, income, or education and should be accounted for in future research on disparities. Recognition of the importance of DPI variables should also stimulate the development and testing of interventions designed to reduce their impact. Finally, DPI analyses facilitate development of shorter measures for clinical use by identifying a few critical clinical domains from among the many in the literature. As surveys become an ever more important tool in routine clinical practice, we expect that prognostic measures such as the DPI will be increasingly incorporated into both research and clinical activities.
Acknowledgments and disclosures
The research for this report was sponsored by grants R01-MH-64658, P50-MH-54623, R01-MH-54444, and MH-63651 from the National Institute of Mental Health; grant R01-HS-08349 from the Agency for Healthcare Research and Quality; grant 96-42901-A-HE from the John D. and Catherine T. MacArthur Foundation; and grant LIP-65-030 from the Department of Veterans Affairs (VA) Health Services Research and Development Center of Excellence for the Study of Healthcare Provider Behavior. The authors thank Scot Hickey, M.A., Bernadette Benjamin, M.A., Carl Elliot, M.S., Hong Vu, M.H.S., and Jose Arbelaez, M.D., Ph.D., for expert programming; Jeff Smith, B.S., Christy Klein, B.A., Maureen Carney, M.A., Chantal Avila, M.A., Carole Oken, M.A., Christine Nelson, B.A., Ray Turner, M.D., M.P.H., and Tracey Hare, B.A., for data collection and data management; Kathryn Magruder, Ph.D., and Paul Nutting, M.D., M.S.P.H., for work on the overall collaborations; and Bob Bell, Ph.D., for statistical consultation. The authors also thank the organizations participating in the studies, including Kaiser Permanente Medical Care Programs in the Northern California Region, Oakland; Department of Veterans Affairs Greater Los Angeles; Ambulatory Sentinel Practice Network, Denver; NYLCare Health Plans of the Mid-Atlantic, Greenbelt, Maryland; Allina Medical Group, Twin Cities, Minnesota; Columbia Medical Plan, Columbia, Maryland; Humana Health Care Plans, San Antonio, Texas; MedPartners, Los Angeles; PacifiCare of Texas, San Antonio; Valley-Wide Health Services, Alamosa, Colorado; Patuxent Medical Group, Patuxent, Maryland; and their associated behavioral health organizations, including Alamo Mental Health Group, San Antonio; San Luis Valley Mental Health/Colorado Health Networks; and Magellan/GreenSpring Behavioral Health, Columbia, Maryland. The authors are also grateful to the clinicians and patients who contributed their time and efforts.
The authors report no competing interests.