Disorganized speech is a key component in the evaluation of psychosis in schizophrenia. Tools for objective measurement remain largely unavailable as current methods of assessment rely on subjective, qualitative clinical examination. However, emerging technologies in artificial intelligence are becoming increasingly capable of performing tasks that require high‐level processing. These advances have the potential to equip psychiatrists with clinical tools to capture objective markers of mental health and improve upon methods for psychiatric assessment.
Natural language processing (NLP) is a branch of artificial intelligence concerned with using computers to interpret conversational human language. NLP can be used to efficiently and inexpensively process large amounts of language data that would otherwise be too time‐consuming or impractical to perform manually. Speech‐to‐text transcripts can be systematically dissected and rated on various language metrics, including coherence and word use patterns. We propose these computational metrics have the potential to provide objective, quantitative markers for patients with disordered speech, such as those with schizophrenia.
Several works have aimed at characterizing language disturbances in schizophrenia with evidence that language markers can discriminate psychosis from normal speech (
1,
2,
3,
4,
5). Compared to healthy controls, people with schizophrenia more often use word approximation (e.g., ‘reflector’ for ‘mirror’ (
6)), invent novel words (i.e., neologisms (
7)), generate ambiguous references and pronouns (
4,
8), show more repetitions in speech (
9,
10,
11,
12), utilize less connectivity between sentences (
13), and display greater use of first‐person singular pronouns (
5,
11,
12,
14,
15). They also tend to use simpler and shorter phrases (
16) and make more syntactic errors (
17). In terms of clinical relevance, language markers can predict the onset of psychosis in prodromal youth with superior accuracy compared to clinical ratings (
2,
3,
18).
Other works have developed computational models that capture increased levels of incoherence and tangentiality in the speech of people with schizophrenia (
1,
2,
3,
4,
5). More recent NLP techniques include BERT (Bidirectional Encoder Representations from Transformers) and RoBERTa (Robustly Optimized BERT Pretraining Approach) (
19,
20). BERT is a machine learning technique for NLP that can be used to perform a wide variety of language‐based tasks, such as text prediction, question answering, and text summarization. BERT employs bidirectional context, which means that it learns information from both left to right and right to left in a text. The bi‐directionality helps the model to understand the context and generate representations. Because the bidirectionality allows for greater context, they tend to perform better than traditional NLP methods. BERT was developed by training on large amounts of texts including Wikipedia and various books, and applying two methods: 1) Masked Language Model to predict randomly masked words, and 2) Next‐sentence Prediction to predict the likelihood of the second sentence following the previous sentence. Applying these techniques allows the model to capture the meaning of the text accurately. Given its relative novelty, the use of BERT in psycholinguistic studies is limited to date. Besides measuring coherence (
5), BERT can also be applied to measure surprisal (
21), which refers to the unexpectedness of a statement given its context. Because individuals with schizophrenia tend to use language in unexpected ways and produce greater language abnormalities compared to healthy individuals, our study takes advantage of BERT's ability to quantify the level of “surprise” in the speech of schizophrenia as a potential language marker.
In this exploratory study, we apply NLP methods to investigate language markers in schizophrenia and their potential role in bringing objectivity to the measurement of psychotic symptoms in an acute clinical setting.
METHODS
Participants
Participants included seven individuals who were admitted to an adult psychiatric inpatient unit during the first wave of enrolment from 2019 to 2021. They were defined by having a documented current clinical diagnosis of schizophrenia with psychosis as the primary reason for admission. Participation excluded non‐English primary speaking language, psychosis attributable to a medical or psychiatric cause other than schizophrenia (e.g., affective psychosis, substance induced psychosis), or inability to participate in verbal interviews for any reason including disability or safety considerations. Comorbid psychiatric diagnoses were present in four participants (previous opioid use disorder, cannabis use disorder, cocaine use disorder, and query seizure disorder). No diagnoses of schizophrenia were revised upon discharge and no participants dropped out of the study.
Participant demographic characteristics are shown in
Table 1. The research ethics review boards at Michael Garron Hospital (784–1901–Mis–333) and the University of Toronto (#00038134) approved the study. All participants provided written informed consent after receiving a complete description of the study.
Enrolment and data collection were paused for extended periods of time in accordance with the review boards' response to the emergence of the COVID–19 pandemic. In the interest of preliminary data analysis, the study sample was limited to the first wave of enrolment. We plan to update this study with data from future enrollment cohorts.
Speech Assay
All subjects participated in a standardized 8‐min interview during their first week of admission and every week thereafter until discharge from hospital. Using instructions adapted from the “free verbalization” interview method described by Reilly et al. (
22), participants were asked to spontaneously talk about two open‐ended interview prompts for 4 min each: 1) any non‐mental health topic of their choosing, and 2) events leading up to their hospitalization. The order of prompts was switched for every other participant. Any personally identifiable information was redacted to protect the participant's privacy. Participants took part in one to five interviews each, depending on their length of hospitalization. Subject responses were audio recorded and transcribed by a third‐party medical transcription service, producing a total of 22 speech‐to‐text samples.
Speech Analysis
Speech pre‐processing
Speech samples were pre‐processed and prepared for computer‐based analyses, which involved eliminating noise and metadata from transcripts (e.g., special characters, timestamps), converting all characters into lowercase, removing stop words, and lemmatizing words (in other words, replacing a word to its base form, e.g., converting “am”, “are”, “is” to “be”; the purpose of lemmatization is to group words with the same root as one item).
Linguistic Features Extracted Using COVFEFE
Linguistic features were extracted at the lexical, syntactic, semantic, and pragmatic levels using the open source tool, COVFEFE (COre Variable Feature Extraction Feature Extractor). A total of 393 features were obtained (
23).
Lexical analysis examines text at the level of individual words, and can measure aspects such as vocabulary richness and lexical norms (e.g., word length, frequency of word use) (
24,
25). Syntactic analysis is concerned with grammar and sentence structure in a text (e.g., noun‐to‐verb ratio, mean length‐of‐sentence) (
26). Semantic analysis is concerned with the literal meaning conveyed by text based on the relatedness of words, phrases, and sentences. Pragmatic analysis focuses on the implicit meaning of text in relation to its context and is a measure of language abstraction (
27). For complete descriptions of all features and algorithms, please refer to Komeilli et al. (
23).
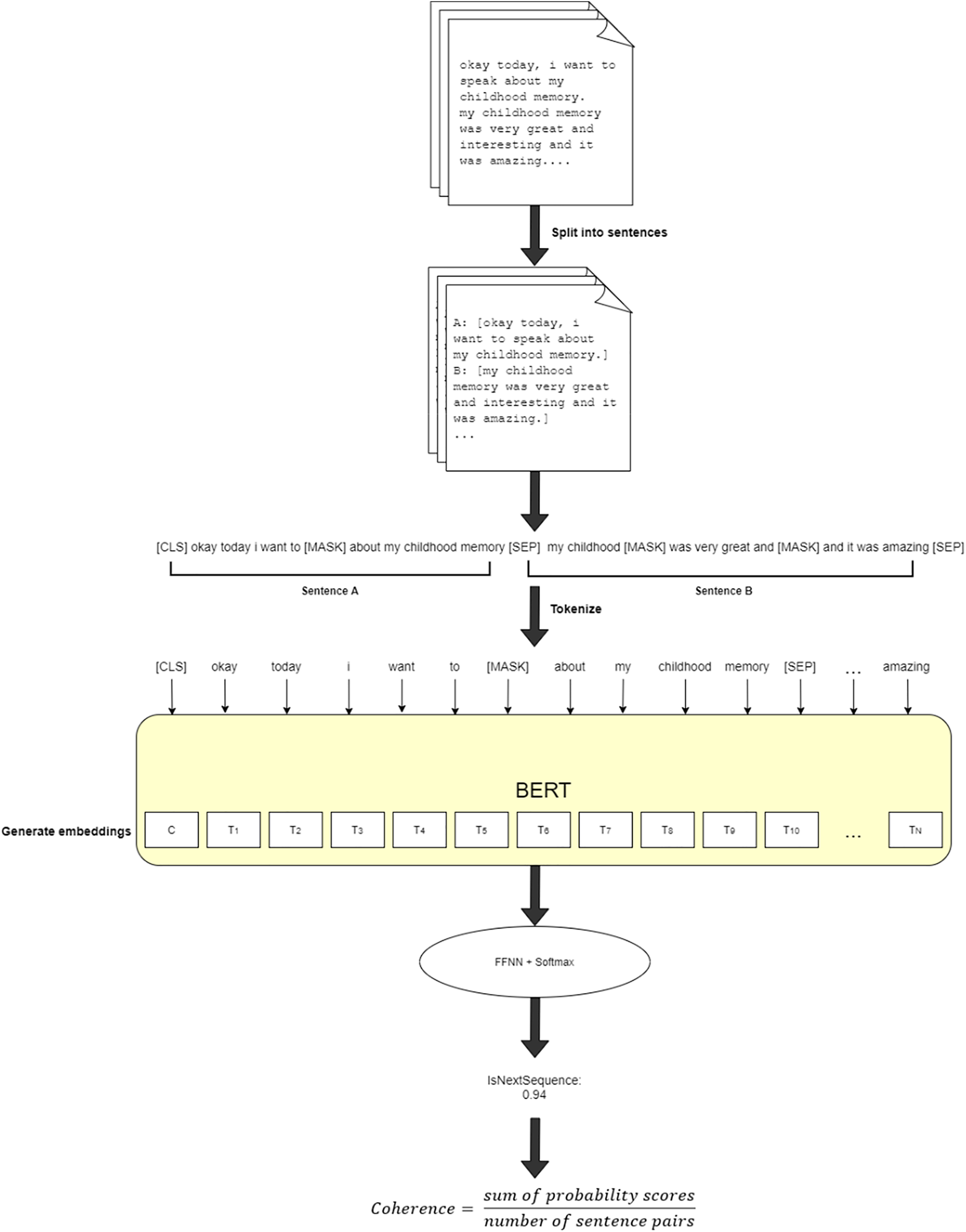
Coherence‐Related Features Extracted Using BERT
The term “incoherent speech” refers broadly to low semantic similarity and disorganized speech associated with formal thought disorder (
1,
4). A common approach to measuring incoherence involves using sentence embeddings, which refers to NLP techniques that map sentences onto numerical vectors in space based on their semantic meaning. Semantic dissimilarity between sentences (incoherence), is derived from the distance between vectors. The embedding technique BERT was used to extract two features: next‐sentence probability and surprisal.
Next‐sentence probability is defined as the probability of a given sentence using the previous sentence as context (
5). The average of these probabilities was computed to measure the overall coherence of the transcript.
Figure 1 illustrates the process of obtaining the coherence feature.
Surprisal refers to the level of unexpectedness of a statement given its context. To calculate surprisal, we use the technique described by Li et al (
21). This technique involves fitting a normal distribution to the embeddings (representation of a language) used by a BERT model. Surprisal is quantified as the likelihood of an utterance occurring according to this distribution. Utterances with higher surprisal are those with a lower likelihood of occurring. Supplementary Figures S2‐S6 shows heatmaps of mean, sum, variance, skweness, and kurtosis of surprisal for each transcript samples.
Correlation of Text Features with Clinical Ratings
At each interview cross‐section, patients were concurrently evaluated with the Scale for the Assessment of Positive and Negative Symptoms (SAPS/SANS) (
28,
29) and the global score of the Scale for the Assessment of Thought, Language, and Communication (TLC) (
30) by attending psychiatrist, author C. G. These clinical rating scales were used to gather observational data on various aspects of speech disorganization, such as tangentiality, incoherence, and illogicality. In addition to language‐related subscales, global scales were included, which consisted of global rating of hallucinations, delusions, bizarre behavior, affective flattening, and avolition/apathy.
We tested whether the extracted linguistic features were associated with the clinical ratings of SAPS, SANS, and TLC scores using Spearman's correlation (
α < 0.05). Bonferroni correction was also applied due to the large number of comparisons and Lilliefors test was performed to check whether the symptom ratings displayed a normal distribution. The features with the highest F‐values were selected for further analysis using the scikit‐learn SelectKBest method (
31).
Machine Learning Prediction of Language Symptom Severity
We predicted the severity of each of the included clinical rating scales using various machine learning models. We used classification algorithms with leave‐one‐subject‐out cross validation method. For classification models, we reported F‐measure and area under the curve (AUC) as evaluation metrics (
32).
RESULTS
Significant Linguistic Features
Among the 393 linguistic features extracted using COVFEFE, 224 resulted in statistically significant correlations at the threshold level of
, with 24 features surviving Bonferroni correction (df = 19 for all correlation tests). Select features that had high predictive power and were relevant to previous literature are presented in
Table 2. All other features that passed the Bonferroni correction are listed in Table S1 in the supplemental data. The strong correlations between certain symptoms and linguistic features are shown in Supplementary Figure S1.
In terms of BERT features, the transcripts had overall next‐sentence coherence ranging from 0.89 to 1.00. Coherence scores were inversely correlated to severity of derailment (r = −0.46, p = 0.033), illogicality (r = −0.50, p = 0.018), and circumstantiality (r = −0.44, p = 0.041). With regards to surprisal, greater surprisal (more negative values) was correlated with increased pressure of speech (r = −0.65, p = 0.001), circumstantiality (r = −0.58, p = 0.0043), illogicality (r = −0.53, p = 0.01), and tangentiality (r = −0.47, p = 0.026). Lower surprisal (more positive values) was correlated with poverty of speech (r = 0.51, p = 0.015).
Machine Learning Models
Machine learning classification models were trained on various combinations of the extracted linguistic features and evaluated on their ability to predict symptom severity from SAPS/SANS and global TLC scores. The top five with the best accuracy are presented in
Table 3. The best performing model was the linear Support Vector Machine, which classified the global rating of alogia (comprising poverty of speech and poverty of content as core elements) with AUC of 1.0 and F‐score of 82% with 29 variables.
DISCUSSION
In this study, we explored the use of automated language analysis to identify objective markers for the positive and negative language symptoms of schizophrenia. Key findings from our analysis are discussed below.
Reduced Lexical Richness and Syntactic Complexity as Markers of Negative Language Symptoms
Participants with more severe symptoms of poverty of speech, poverty of content, and social inattentiveness generally displayed reduced lexical richness and syntactic complexity, as demonstrated by substantially lower Honoré’s statistics, shorter word lengths, increased use of high‐frequency words, shorter mean sentence and clause lengths, and fewer occurrences of coordination and prepositions. These findings are in accordance with previous studies that suggest an important relationship between symptoms of schizophrenia and linguistic complexity (
11,
13,
16), and our work shows this relationship can be measured objectively.
Lower Content and More Repetitions Associated with Derailment and Pressure of Speech
Participants who scored higher in derailment and pressure of speech objectively used considerably more words, clauses, and sentences, as well as longer sentences, but lower type‐token ratio and content density. Type‐token ratio is the number of unique words divided by the total number of words. These results support that decreased type‐token ratio and content density are indicators of diminished lexical diversity and deficit of meaningful information in discourse. Additionally, lower type‐token ratio despite longer utterances may be an indicator of repetitive speech. These results offer possible objective metrics for capturing aspects of disorganized speech.
Lower Next‐Sentence Probability as a Marker for Incoherence, Surprisal Linked to Longer Sentences
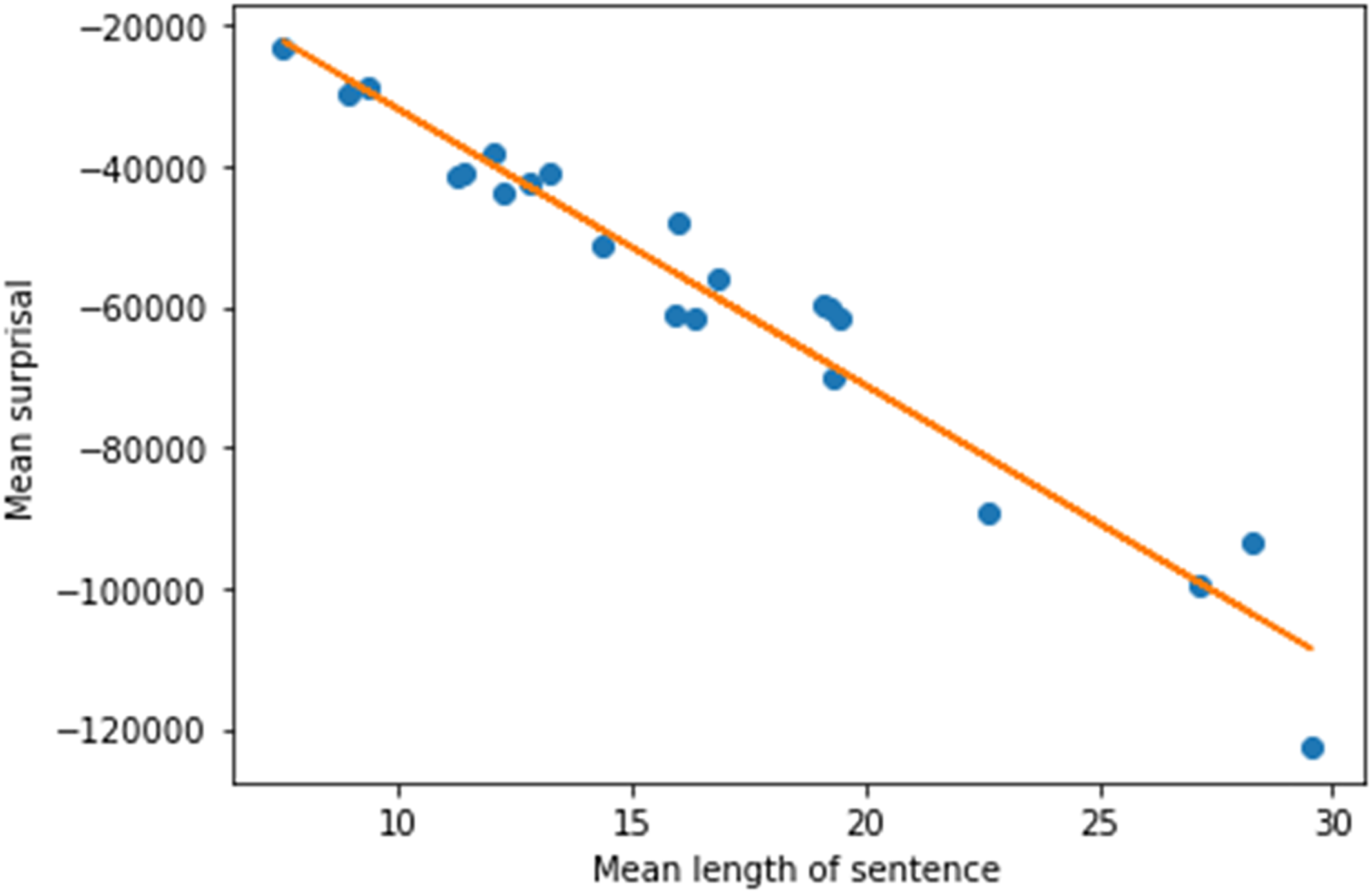
Lower BERT next‐sentence probability scores corresponded to severity of clinically observed derailment, illogicality, and circumstantiality. BERT surprisal was more prevalent among transcripts with elevated pressure of speech and attenuated poverty of speech. Our findings suggest that samples with greater speech production were more “surprising” than samples with lower amount of speech.
Figure 2 demonstrates the strong correlation between surprisal and mean length of sentence. Supplementary Figure S7 shows a heatmap of surprisal for two transcript samples at a sentence level, with the longest sentence indicating greater surprisal.
Machine Learning Models
Our work on machine learning classification revealed that global rating of alogia, illogicality, poverty of speech, social inattentiveness, and global TLC score can be predicted with up to 82% accuracy (0.82 F1 score). Our model distinguishes the severity of alogia with the highest accuracy. This value is comparable to results from other NLP studies which have yielded accuracies of 69–75% (
33), 78.4–87.5% (
1), and 93% (
4) and outperformed human raters who performed at 65.4–71.9% (
1). Tang et al. (
5) explored BERT's sentence‐level coherence in schizophrenia spectrum disorders, demonstrating greater tangentiality among patients than controls with 87% accuracy. The particularly intriguing aspect of this work was that NLP methods revealed superior ability to detect subclinical differences (sentence coherence using BERT scores, log‐odds ratio, parts‐of‐speech counts, and incomplete word counts) between patients and controls compared to purely human clinical ratings. Our preliminary results demonstrate that NLP can be used to predict symptom severity from speech records. This may have applications in enhancing the objectivity of psychiatric symptom assessment and mental status examination, particularly in situations where speech data may be the only information available at the time, such as, telephone assessments, voicemail, forensic evidence, etc.
Strengths and Weaknesses of the Study
This exploratory study has a few notable strengths. First, it takes into account the complex heterogeneity of schizophrenia, where the presence of symptoms varies between individuals, and symptoms may change over time. Previous studies have almost exclusively focused on dichotomous classification between patients and controls, which overlooks the diversity of symptom profiles, whereas our study investigates the severity of individual symptoms for each participant. Second, the data were collected from a real‐world clinical setting and psychiatric comorbidities in addition to schizophrenia were permissible for eligibility. While this study focuses on psychosis related to schizophrenia, we eschewed overly rigid exclusion criteria to reflect the fact that patients often transcend diagnostic categories and accurate monitoring of psychotic symptom burden is no less important in the presence of comorbidities. Finally, the design of the free verbalization interview helped to minimize repetition and practice effects within subjects, and allows our method to be applied to naturalistic spontaneous speech without the need to administer a separate questionnaire or structured interview.
On the other hand, there are limitations that warrant caution in the interpretation of this exploratory study. The sample size is small compared to generic machine learning datasets; prospective research with larger groups may improve sensitivity in detecting differences in individual dimensions. The biggest unexpected challenge to recruitment was the COVID–19 pandemic, which introduced exposure risk inherent to conducting interviews for data collection. This will likely need to be considered as a potential risk in the design of future studies in this area. Furthermore, sampling bias may have also been a factor given that participants were required to be capable of consent to participate in research and willingly have their speech recorded for analysis, which may have resulted in those with more severe disorganization, or paranoia about recording devices, less likely to participate. This could account for the relatively high next‐sentence coherence scores among the sample (0.89–1.00), suggestive of less severe disorganization.
Our study also relies on the assumption that the attending psychiatrist's clinical ratings reflect the patient's true mental state and symptomatology. In other words, the “gold standard” against which the language markers were compared is prone to the very same issues of subjectivity and reliability we sought to improve upon in our search for objective markers. If resources permitted, enlisting multiple raters with measured agreement would have strengthened the validity of clinical ratings as the “gold standard” comparison. Although this remains a limitation, we believe the assumption is generally justified given the psychiatrist is clinically experienced and completed the scales based on all the available clinical information up to that point in time during the subject's hospitalization. We also reduced bias from subjectivity by using scales which have been psychometrically validated for inter‐rater reliability.
In terms of other limitations, our method used third‐party manual transcription services to translate speech recordings into text for analysis. In practice, this would pose a cost prohibitive barrier and administrative burden for implementation in routine assessments. However, with advances in speech‐to‐text software, this step could be automated for real‐time, point‐of‐care language testing and scoring. Direct analysis of the speech audio itself could also be valuable for non‐verbal speech cues, such as pitch, tone, vocal inflection, and pause duration. These are often important aspects of mental status examination, and several studies have shown that non‐verbal speech measures can be applied to accurately quantify negative symptoms (
34,
35,
36). Therefore, combining acoustic and linguistic components might allow for better predictive power in our empirical tests.
CONCLUSION
The goal of this small exploratory study was to find linguistic markers of psychosis that can be used to objectively measure disorganized speech and symptom severity in schizophrenia. We found reduced lexical richness and syntactic complexity as characteristic of negative language symptoms (poverty of speech, poverty of content, social inattentiveness), while lower content density and more repetitions in speech as predictors of positive language symptoms (derailment, pressured speech). We also demonstrated methods for objectively measuring incoherent speech using state‐of‐the‐art neural network models (i.e., BERT). These preliminary findings highlight the potential advantages of applying computational NLP methods as a clinical assessment tool, thus creating a framework for objective measurement‐based care in schizophrenia.