Despite increased attention to suicide prevention, U.S. suicide rates continue to rise—increasing by more than one-third since 1999 (
1). Over three-quarters of individuals attempting or dying by suicide had at least one outpatient health care visit during the previous year (
2,
3). Health care encounters are a natural setting for identifying and addressing risk for suicidal behavior (
4), but effective prevention requires accurate identification of risk. Unfortunately, assessments based on traditional risk factors are not accurate enough to direct interventions to those at highest risk (
5,
6). Results from recent research indicate that statistical models, which are often based on electronic health records (EHRs), more accurately identify patients at high risk for suicide in mental health, general medical, and emergency department settings (
7–
12). Motivated by that research, some health care systems have implemented risk prediction models as a component of population-based suicide prevention (
13). At the same time, some have questioned whether statistical predictions can really inform clinician decisions, given concerns regarding high false-positive rates, potential for false labeling, and lack of transparency or interpretability (
14).
Current (
13) and planned implementations of suicide risk prediction models typically call for delivering statistical predictions to treating clinicians. Clinicians then assess risk and implement specific prevention strategies (e.g., collaborative safety planning [
15]) or treatments (e.g., cognitive-behavioral therapy [
16] or dialectical behavior therapy [
17]). This sequence presumes that clinician assessment improves on a statistical prediction. Whether or not a clinician assessment adds to statistical risk predictions, however, depends on whether those two methods are competing, complementary, or simply duplicative approaches.
In June 2019, the National Institute of Mental Health convened a meeting, “Identifying Research Priorities for Risk Algorithms Applications in Healthcare Settings to Improve Suicide Prevention” (
18). The meeting considered a range of clinical, technical, and ethical issues regarding implementation of prediction models. As participants in that meeting, we present in this article our conclusions and recommendations, which are based on discussions during and after the meeting. We focus on one central issue: how algorithms or statistical predictions might complement, replace, or compete with traditional clinician prediction. First, we attempt to clarify conceptual and practical differences between suicide predictions by clinicians and predictions from statistical models. Second, we review the limited evidence available regarding accuracy of and concordance between these two methods. Third, we present a conceptual framework for understanding agreement and disagreement between clinician-based and statistical predictions. Finally, we identify priorities for improving data regarding suicide risk and propose priority questions for research.
Although we focus on prediction of suicidal behavior, clinicians can expect to encounter more frequent use of statistical models to predict other clinical events, such as psychiatric hospitalization (
19) or response to antidepressant treatment (
20). We hope that the framework we describe in the following can broadly inform research and policy regarding the integration of statistical prediction and clinician judgment to improve mental health care.
Defining and Distinguishing Statistical and Clinician Prediction
We define statistical prediction as the use of empirically derived statistical models to predict or stratify risk for suicidal behavior. These models might be developed by using traditional regression or various statistical learning methods, but their defining characteristic is the development of a statistical model from a large data set with the aim of applying this model to future practice. We define clinician prediction as a treating clinician’s estimate of risk during a clinical encounter. As summarized in
Table 1, statistical and clinician predictions typically differ in the predictors considered, the process for developing predictions, the nature of the resulting prediction, and the practicalities of implementation.
Inputs for Generating Predictions
Data available to statistical models and data available to clinicians overlap only partially. Statistical models to predict suicidal behavior typically consider hundreds or thousands of potential predictors extracted from health records data (EHRs, insurance claims, and hospital discharge data) (
21). These data most often include diagnoses assigned, prescriptions filled, and types of services used but could also include information extracted from clinical text or laboratory data (
22,
23). Statistical models may also consider “big data” not typically included in health records, such as genomic information, environmental data, online search data, or social media postings (
24,
25). In contrast, clinician reasoning is typically limited to a handful of predictors. Clinicians, however, can consider any data available during a clinical encounter, ranging from unstructured clinical interviews to standardized assessments tools (
26–
29). Most important, clinician assessment usually considers narrative data systematically recorded in EHRs, such as stressful life events, and subjective information, such as clinicians’ observations of thought processes or nonverbal cues (
30,
31).
Prediction Process
Statistical and clinician predictions differ fundamentally in accommodating high dimensionality and heterogeneity of predictive relationships. Statistical methods select among large numbers of correlated predictors and assign appropriate weights in ways a human clinician cannot easily replicate. The statistical methods for reducing dimensionality involve choices and assumptions that may be obscure to both clinicians and patients. In contrast, clinician prediction relies on individual judgment to select salient risk factors for individuals and assign each factor greater or lesser importance. Statistical prediction reduces dimensionality empirically, and clinician prediction reduces dimensionality by using theory, heuristics, and individual judgment.
Statistical models account for heterogeneity or complexity by allowing nonlinear relationships and complex interactions between predictors. Clinician prediction may consider interactions among risk factors but in a subjective rather than a quantitative sense. For example, clinicians might be less reassured by absence of suicidal ideation for a patient with a history of unplanned suicide attempt.
Statistical predictions typically produce a continuous risk score rather than a dichotomous classification. Selecting a threshold on that continuum must explicitly balance false-negative and false-positive errors. A higher threshold (less sensitive and more specific) is appropriate when considering an intervention that is potentially coercive or harmful. Machine-learning methods for developing risk scores also permit explicit choices regarding loss or cost functions that emphasize accuracy in different portions of the risk spectrum. Although clinician prediction may consider the relative importance of false-negative and false-positive errors, that consideration usually is not explicit or quantitative.
Outputs or Products
Statistical prediction typically has narrower goals than does clinician prediction. Statistical models simply identify associations in large samples and combine these associations to optimize a unidimensional prediction, that is, the probability of suicidal behavior during a specific period. The resulting statistical models are optimized for prediction but often have little value for explanation or causal inference. Even when statistical models consider potentially modifiable risk factors (e.g., alcohol use), statistical techniques used for prediction models are not well suited to assess causality or mechanism. In contrast, clinician prediction considers psychological states or environmental factors to generate a multidimensional formulation of risk. Explanation and interpretation are central goals of clinician prediction.
Because statistical prediction values optimal prediction over interpretation, statistical models can paradoxically identify treatments appropriate for suicide prevention (such as starting a mood stabilizer medication) as risk factors. Recent discussion underlines the importance of properly modeling interventions in prognostic models to prevent this phenomenon (
32). In contrast, clinician prediction often aims to identify modifiable risk factors as treatment targets. For example, hallucinations regarding self-harm would be both an indicator of risk and a target for treatment.
Implementing Predictions in Practice
The abovementioned differences in inputs and processes have practical consequences for implementation of predictions. Statistical prediction occurs outside a clinical encounter through use of data readily accessible to statistical models. Clinician prediction occurs in real time during face-to-face interactions. Statistical prediction is performed in large batches, with accompanying economies of scale. Clinician prediction is, by definition, a handcrafted activity. Detailed clinician assessment may not be feasible in primary care or other settings where clinician time or specialty expertise is limited. In contrast, statistical prediction may not be feasible in settings without access to comprehensive electronic records.
The boundary between statistical prediction and clinician prediction is not crisply defined. Statistical prediction models may consider subjective information extracted from clinical texts (
33). Clinician prediction may include use of risk scores calculated from structured assessments or checklists (
6). Additionally, clinicians determine what information is entered into medical records and thus available for statistical predictions. Despite this imprecise boundary, we believe that the distinction between statistical and clinician predictions has both practical and conceptual importance.
Empirical Evidence on Accuracy and Generalizability of Statistical and Clinician Predictions
Little systematic information is available regarding the accuracy of clinicians’ predictions in everyday practice. Outside of research settings, clinicians’ assessments are not typically recorded in any form that would allow for formal assessment of accuracy or comparison to a statistical prediction. Nock and colleagues (
34) reported that predictions by psychiatric emergency department clinicians were not significantly associated with probability of repeat suicidal behavior among patients presenting after a suicide attempt. A meta-analysis by Franklin and colleagues (
5) found that commonly considered risk factors (e.g., psychiatric diagnoses, general medical illness, and previous suicidal behavior) are only modestly associated with risk for suicide attempt or suicide death. That finding, however, may not apply to clinicians’ assessments that use all data available during a clinical encounter. Any advantage of clinician prediction probably derives from use of richer information (e.g., facial expression and tone of voice) and from clinicians’ ability to assess risk in novel individual situations. No published data have examined the accuracy of real-world clinicians’ predictions in terms of sensitivity, positive predictive value, or overall accuracy (i.e., area under the curve [AUC]).
Some systematic data are available regarding accuracy of standard questionnaires or structured clinician assessments. For example, outpatients reporting thoughts of death or self-harm “nearly every day” on the 9-item Patient Health Questionnaire (PHQ-9) depression instrument (
35) were eight to 10 times more likely than those reporting such thoughts “not at all” to attempt or die by suicide in the following 30 days (
27). Among Veterans Health Administration (VHA) outpatients, the corresponding odds ratio was ∼3 (
36). Nevertheless, this screening measure has significant shortcomings in both sensitivity and positive predictive value. More than one-third of suicidal behaviors within 30 days of completing a PHQ-9 questionnaire occurred among those reporting suicidal ideation “not at all” (
27). The 1-year risk for suicide attempt among those reporting suicidal ideation “nearly every day” was only 4%. The Columbia–Suicide Severity Rating Scale has been reported to predict suicide attempts among outpatients receiving mental health treatment when administered either by clinician interview or by electronic self-report (
26,
37). The Columbia scale has shown overall accuracy (AUC) of ∼80% in predicting future suicide attempts among U.S. veterans entering mental health care (
38) and individuals seen in emergency departments for self-harm (
39).
Statistical models developed for a range of clinical situations (e.g., active duty soldiers [
9,
40], large integrated health systems [
11], academic health systems [
7,
41], emergency departments [
12], and the VHA [
8]) all appear to be substantially more accurate than predictions based on clinical risk factors or structured questionnaires. Overall classification accuracy as measured by AUC typically exceeds 80% for statistical prediction of suicide attempt or suicide death, clearly surpassing the accuracy rates of 55%–60% for predictions based on clinical risk factors. Overall accuracy of statistical models (
7–
9,
11) also exceeds that reported for self-report questionnaires (
27,
36) or structured assessments (
26,
37–
39). Nearly half of suicide attempts and suicide deaths occurred among patients with computed risk scores in the highest 5% (
7–
9,
11), an indicator of practical utility in identifying a group with 10-fold elevation of risk.
Comparison of overall accuracy across samples (clinician prediction assessed in one sample and statistical prediction in a different sample), however, cannot inform decisions about how the two methods can be combined to facilitate suicide prevention. The future of suicide risk assessment will likely involve a combination of statistical and clinician predictions (
42). Rather than framing a competition between the two methods, we should determine the optimal form of collaboration. Informing that collaboration requires detailed knowledge regarding how alternative methods agree or disagree.
Few data are available from direct comparisons of statistical predictions and clinician assessments within the same patient sample. Among ambulatory and emergency department patients undergoing suicide risk assessment, a statistical prediction from health records was substantially more accurate than clinicians’ assessments that used an 18-item checklist (
10). Of patients identified as being at high risk by the VHA prediction model, the proportion “flagged” as high risk by treating clinicians ranged from approximately one-fifth for those with statistical predictions above the 99.9th percentile to approximately one-tenth for those with statistical predictions above the 99th percentile (
43). Among outpatients treated in seven large health systems, adding item 9 of the PHQ-9 to statistical prediction models had no effect for mental health specialty patients and only a slight effect for primary care patients (
44).
Although these data suggest substantial discordance between statistical predictions and clinician predictions, they do not identify patient, provider, or health system characteristics associated with such disagreements. Available data also do not enable us to examine how statistical and clinician predictions agree by using higher or lower risk thresholds or over shorter versus longer periods. Theoretically, statistical prediction can consider information available within and beyond EHRs. In statistical prediction models reported to date, however, the strongest predictors remain psychiatric diagnoses, mental health treatments, and record of previous self-harm (
7–
11). Thus, statistical predictions still rely primarily on data created and recorded by clinicians. Any advantage of statistical prediction derives not from access to unique data but from rapid complex calculation not possible for clinicians.
Prediction models based on EHR data could replicate or institutionalize bias or inequity in health care delivery (
45). Given large racial and ethnic differences in suicide mortality rates (
46), a statistical model considering race and ethnicity would yield lower estimates of suicide risk for some traditionally underserved groups (
44). A model not allowed to consider race and ethnicity would yield less accurate predictions. Whether and how suicide risk predictions should consider race and ethnicity is a complex question. But the role of race and ethnicity in statistical predictions is at least subject to inspection, whereas biases of individual clinicians cannot be directly examined or easily remedied.
Any prediction involves applying knowledge based on previous experience. For either statistical or clinician prediction to support clinical decisions, knowledge regarding risk for suicidal behavior developed in one place at one time should still serve when transported to a later time, a different clinical setting, or a different patient population. Published data regarding transportability or generalizability, however, are sparse. Understanding the logistical and conceptual distinctions between statistical and clinician predictions, we can identify specific concerns regarding generalizability for each method. Because clinician prediction depends on the skill and judgment of human clinicians to assess risk, we must consider how clinicians’ abilities might vary across practice settings and how clinicians’ decisions might be influenced by the practice environment. Because statistical prediction usually depends on data elements from EHRs to represent underlying risk states, we must consider how differences in clinical practice, documentation practices, or data systems would affect how specific EHR data elements are related to actual risk (
44). Clinical practice or documentation could vary among health care settings or within one health care setting over time (
47). Even if statistical methods apply equally well across clinical settings, the resulting models may differ in predictors selected and weights applied (
48).
Understanding Disagreement Between Statistical and Clinician Predictions
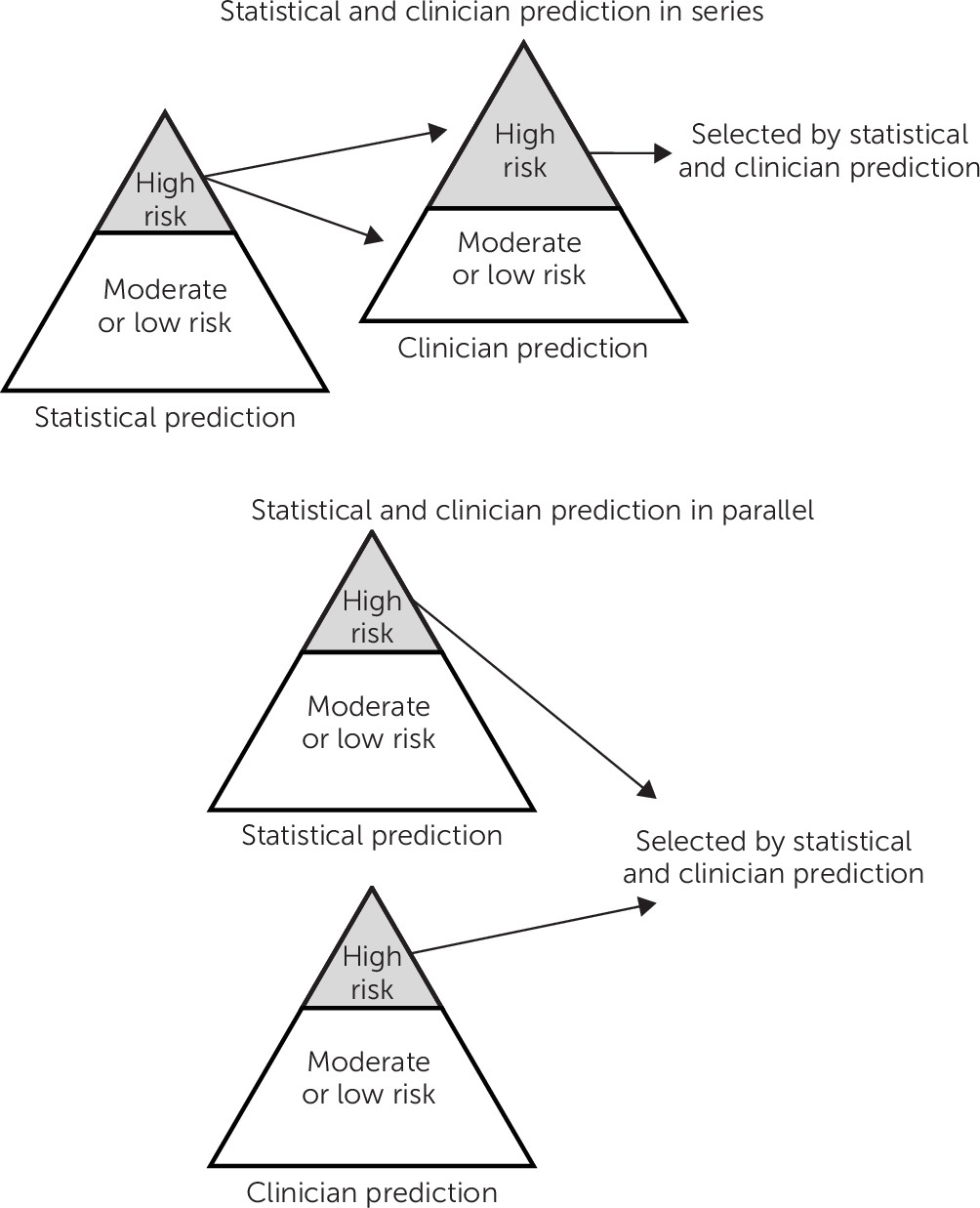
Current (
13) and planned implementations of statistical prediction models have typically called for a two-step process, with statistical and clinician predictions operating in series. That scheme is shown at the top of
Figure 1, simplifying risk as a dichotomous state. Statistical predictions are delivered to human clinicians, who then evaluate risk and initiate appropriate interventions. This two-step process may or may not be reasonable, depending on how we understand the relationship between statistical and clinician risk predictions. Those two processes may estimate the same or different risk states or estimands. Understanding similarities and differences in the risk states or estimands of statistical and clinician predictions is essential to optimally combining these potentially complementary tools.
If statistical and clinician predictions are imperfect measures of the same underlying risk state or estimand, applying these tools in series may be appropriate. Even if clinician prediction is less accurate on average than statistical prediction, combining the two may improve overall accuracy. Statistical predictions can be calculated efficiently at large scale, whereas clinician prediction at the level of individual encounters is more resource intensive. Consequently, it would be practical to compute statistical predictions for an entire population and reserve detailed clinician assessment and clinician prediction for those above a specific statistical threshold (
Figure 1, top). Such an approach would be especially desirable if clinician prediction were more accurate for patients in the upper portion of the risk distribution (i.e., those identified by a statistical model as needing further clinician assessment).
We can, however, identify a range of scenarios when a series arrangement would not be optimal. Statistical and clinician predictions could identify different underlying risk states or estimands. For example, statistical models might be more accurate for identifying sustained or longer-term risk, whereas clinician assessment could be more accurate for identifying short-term or imminent risk. Alternatively, statistical and clinician predictions could also identify distinct pathways to the same outcome. For example, clinician prediction might better identify unplanned suicide attempts, and statistical prediction might identify suicidal behavior after a sustained period of suicidal ideation. Finally, statistical and clinician predictions might identify risk in different populations or subgroups. For example, statistical models could be more accurate for identifying risk among those with a known mental disorder, whereas clinician assessment could be more accurate for identifying risk among those without a mental disorder diagnosis. In any of these scenarios, we should implement statistical and clinician predictions in parallel rather than in series. That parallel logic is illustrated at the bottom of
Figure 1. We would not limit clinician assessment to persons identified by a statistical model or allow clinician assessment to override an alert based on a statistical model. Instead, we would consider each as an indicator of suicide risk.
More complex combinations of statistical and clinician prediction methods might lead to optimal risk prediction. Logical combination of two imperfect measures may improve both accuracy and efficiency (
49). Clinician assessment might be guided or informed by results of statistical predictions, with tailoring of clinician assessment based on patterns detected by statistical models. For example, clinicians might employ specific risk assessment tools for patients identified because of substance use disorder and different tools for patients identified because of a previous suicide attempt.
Effective prevention requires more than accurate risk predictions. Both statistical and clinician predictions aim to guide the delivery of preventive interventions, most likely delivered by treating clinicians. The discussion above presumes that statistical and clinician predictions aim to inform similar types of preventive interventions. But just as statistical and clinician predictions may identify different types of risk, they may be better suited to inform different types of preventive interventions. However, for both statistical and clinician predictions, we again caution against confusing predictive relationships with causal processes or intervention targets. If recent benzodiazepine use is selected as an influential statistical predictor, this selection does not imply that benzodiazepines cause risk or that interventions focused on benzodiazepine use would reduce risk. Compared with statistical models, clinicians may be better able to identify unmet treatment needs, but correlation does not equal causation (or imply treatment effectiveness) for clinician or statistical prediction. Caution is warranted regarding causal inference even for risk factors typically considered to be modifiable, such as alcohol use or severity of anxiety symptoms.
Priorities for Future Research
Rather than framing statistical and clinician predictions of suicide risk as competing with each other, future research should address how these two approaches could be combined. At this time, we cannot distinguish between the scenarios described above to rationally combine statistical and clinician predictions. We can, however, identify several specific questions that should be addressed by future research.
Addressing any of these questions will require accurate data regarding risk assessment by real-world clinicians in actual practice. Creating such data would depend on routine documentation of clinicians’ judgments based on all data at hand. This could be accomplished through use of some standard scale allowing for individual clinician judgment in integrating all available information. The widely used Clinical Global Impressions scale and Global Assessment of Functioning scale are examples of such clinician-rated standard measures of symptom severity and disability. Clearer documentation regarding clinicians’ assessment of suicide risk would seem to be an essential component of high-quality care for people at risk for suicidal behavior, but changing documentation standards would likely require action from health systems or payers. In addition, data regarding clinicians’ risk assessment should be linked with accurate and complete data on subsequent suicide attempts and suicide deaths. Systematic identification of suicidal behavior outcomes is essential for effective care delivery and quality improvement, independently of any value for research. With an adequate data infrastructure in place, we can then address specific questions regarding the relationship between statistical and clinician predictions of suicidal behavior.
First, we must quantify agreement and disagreement between statistical and clinician predictions by using a range of risk thresholds. This quantification would require linking data from clinicians’ assessments to statistical predictions by using data available before the clinical encounter. Any quantification of agreement should include the same at-risk population and should consider the same outcome definition(s) and outcome period(s). Ideally, quantification of agreement should consider risk predictions at the encounter level (how methods agree in identifying patients at high risk during a health care visit) and at the patient level (how methods agree in identifying patients at high risk in a defined population).
Second, after identifying overall discordance between predictions, we should examine actual rates of suicidal behavior among those for whom predictions were concordant (i.e., high or low risk by both measures) or discordant (high statistical risk but not high risk by clinician assessment or vice versa). Addressing this question would require linking data regarding both statistical and clinician predictions to population-based data on subsequent suicide attempt or death. If these two methods are imperfect measures of the same risk state, we would expect risk in both discordant groups to be lower than that in concordant groups. Equal or higher risk in either discordant group would suggest that one measure identifies a risk state not identified by the other measure.
Third, we should quantify disagreement and compare performance within distinct vulnerable subgroups: those with specific diagnoses (e.g., psychotic disorders or substance use disorders), groups known to be at high risk (e.g., older men or Native Americans), or groups for whom statistical prediction models do not perform as well (e.g., those with minimal or no history of mental disorder diagnosis or mental health treatment). Either statistical prediction or clinician prediction may be superior in any specific subgroup.
Fourth, we should examine how predictions operate in series (i.e., how one prediction method adds meaningfully to the other). As discussed above, practical considerations argue for statistical prediction to precede clinician assessment. That sequence presumes that clinician assessment adds value to predictions identified by a statistical model. Previous research regarding accuracy of clinician prediction has typically examined overall accuracy and not accuracy conditional on a prior statistical prediction. Relevant questions include, Does clinician assessment improve risk stratification among those identified as being at high risk by a statistical model? How often does clinician assessment identify risk not identified by a statistical model? Is clinician prediction of risk more or less accurate in subgroups with specific patterns of empirically derived predictors (e.g., young people with a recent diagnosis of psychotic disorder).
Finally, we should examine the effects of specific interventions among those identified by statistical and clinician predictions of suicide risk. Clinical trials indicating the risk-reducing effects of either psychosocial or pharmacological interventions have typically included participants identified by clinicians or selected according to clinical risk factors. We should not presume that these interventions would prove equally effective among individuals identified by statistical predictions. Addressing this question would likely require large pragmatic trials, not limited to those who volunteer to receive suicide prevention services. If statistical prediction identifies different types or pathways of risk, those identified by statistical models might experience different benefits or harms from treatments developed and tested in clinically identified populations.
Conclusions
We anticipate both that statistical prediction tools will see increasing use and that clinician prediction will continue to improve with the development of more efficient and accurate assessment tools. Consequently, the future of suicide risk prediction will likely involve some combination of these two methods. Rational combination of traditional clinician assessment and new statistical tools will require both clear understanding of the potential strengths and weaknesses of these alternative methods and empirical evidence for how these strengths and weaknesses affect clinical utility across a range of patient populations and care settings.