Step 2: survey of relevant literature
Our interest in calibrating our selection process with measures used in efficacy or effectiveness treatment studies led to a computerized search of more than 30 bibliographic databases—for example, PsycINFO, MEDLINE, Social SciSearch, and ERIC. This approach yielded nearly 500 citations published between 1990 and 2002 by using the search terms "severe and persistent and mental and ill or SPMI," "severe and mental and ill or SMI," and "schizophrenia and outcome and inpatient." Studies conducted before 1990 were excluded to limit bias toward older instruments, and instruments were not counted more than once if they were used in multiple articles associated with a single investigation.
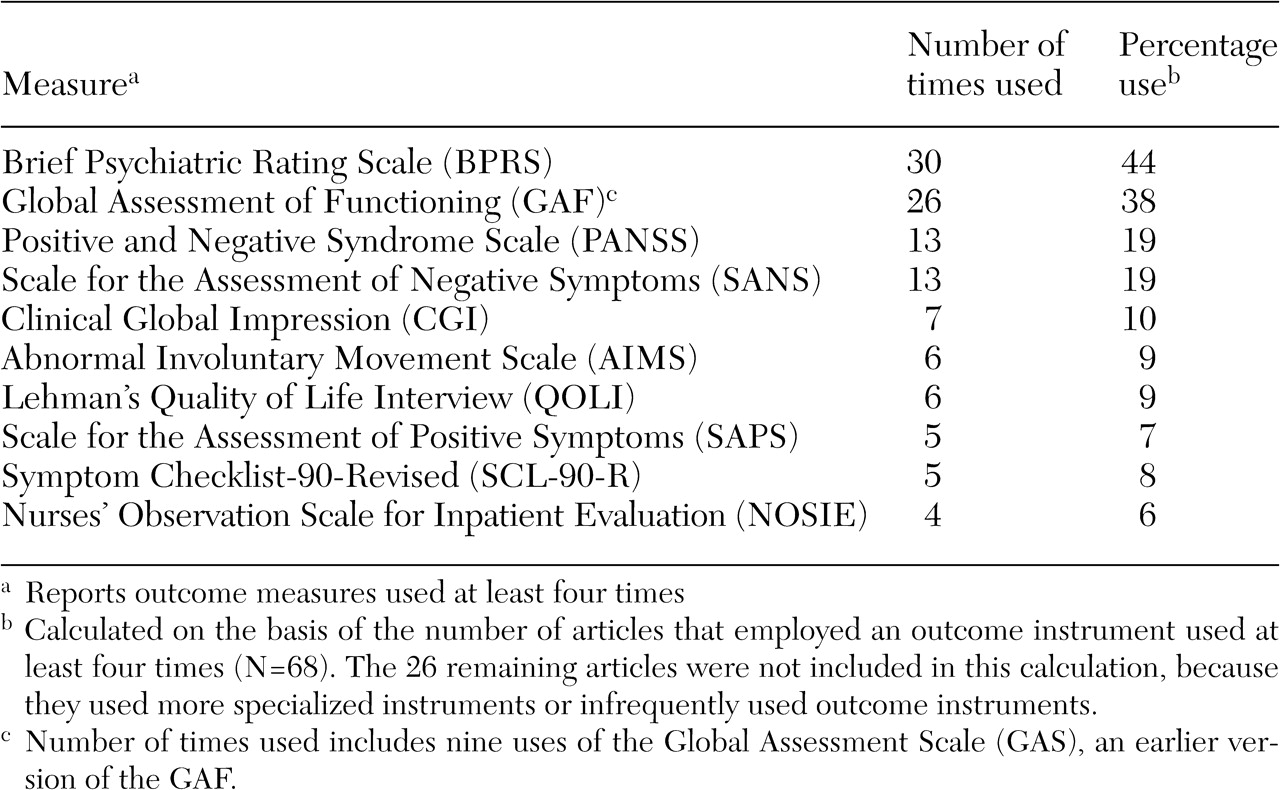
Only 94 citations (20 percent) were treatment evaluation studies that used standardized outcome measures (
Table 1). Excluded citations included conceptual or policy papers, reviews, studies of process or structure measures, or nonstandardized outcomes measures—for example, dropout rates, cost, and recidivism. The sample produced 110 measures, with 11 (10 percent) used at least four times, three (3 percent) used three times, 15 (14 percent) used twice, and 81 (74 percent) used just once. Interestingly, 25 measures (23 percent) were investigator created; it has been argued that such measures provide meaningless comparative information (
48).
Three observations were drawn from the results of the survey (
Table 1). First, the clinician-rated measures that were used most often included the Brief Psychiatric Rating Scale (BPRS) (
49), the Global Assessment of Functioning (GAF) (
50), the Positive and Negative Syndrome Scale (PANSS) (
51), and the Scale for the Assessment of Negative Symptoms (SANS) (
52). The BPRS was used twice as frequently (44 percent) as the PANSS and the SANS.
Second, very few self-report instruments had repeated use. Only two self-report outcome measures surfaced in four or more studies, including the Symptom Checklist-90-Revised (SCL-90-R) (
53) and the Quality of Life Interview (QOLI) (
54). Third, multiple-measure assessment was preferred over single-measure protocols by a ratio of 2 to 1. This finding mirrors recommendations that a single source may be less reliable because each source contributes a valid yet potentially divergent perspective (
55). Although the average number of measures used per study was 2.8 (range, one to 13), what was striking was the number of studies (N=30) that used a single outcome instrument.
Step 4: comparison of frequently used instruments
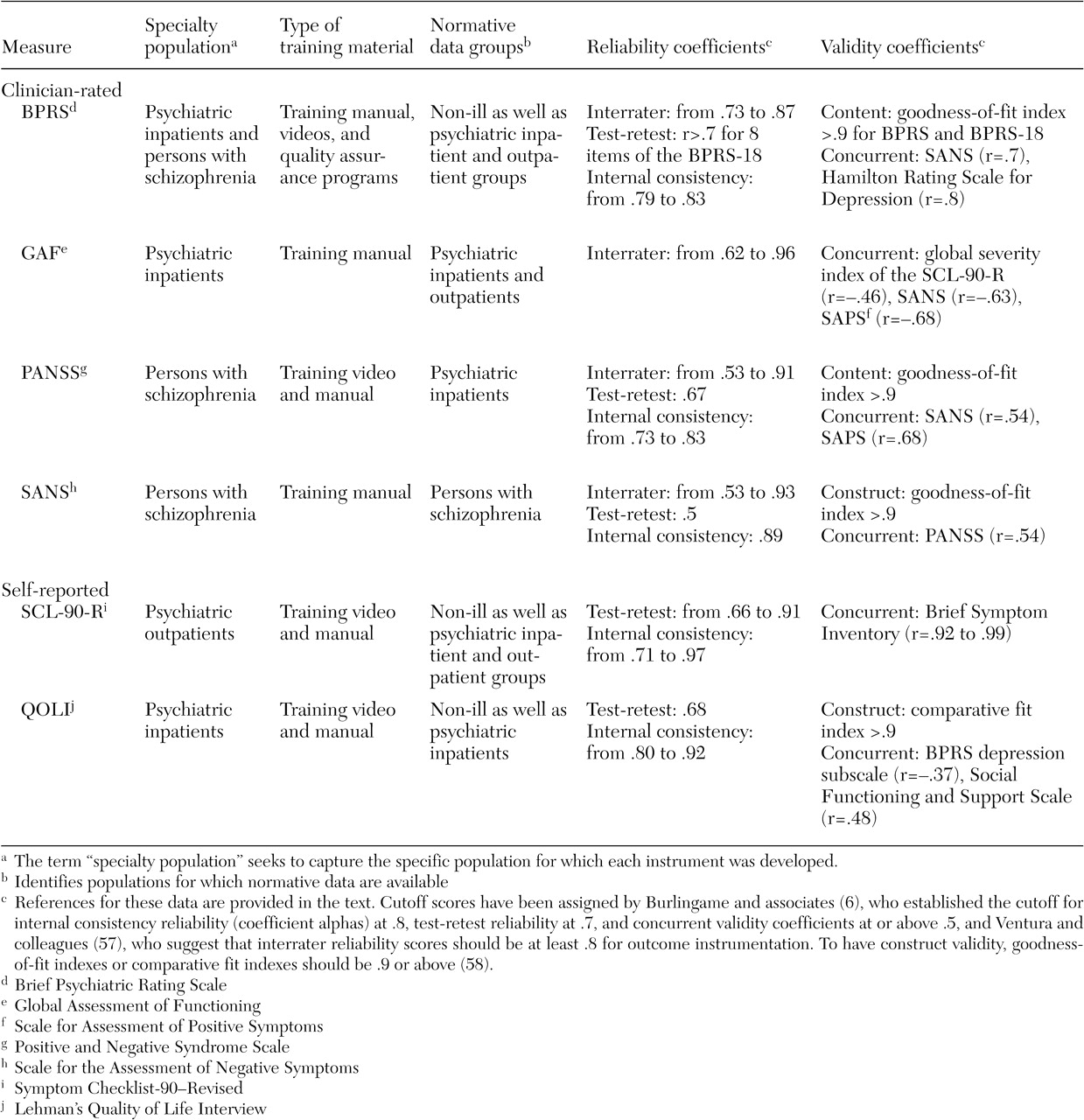
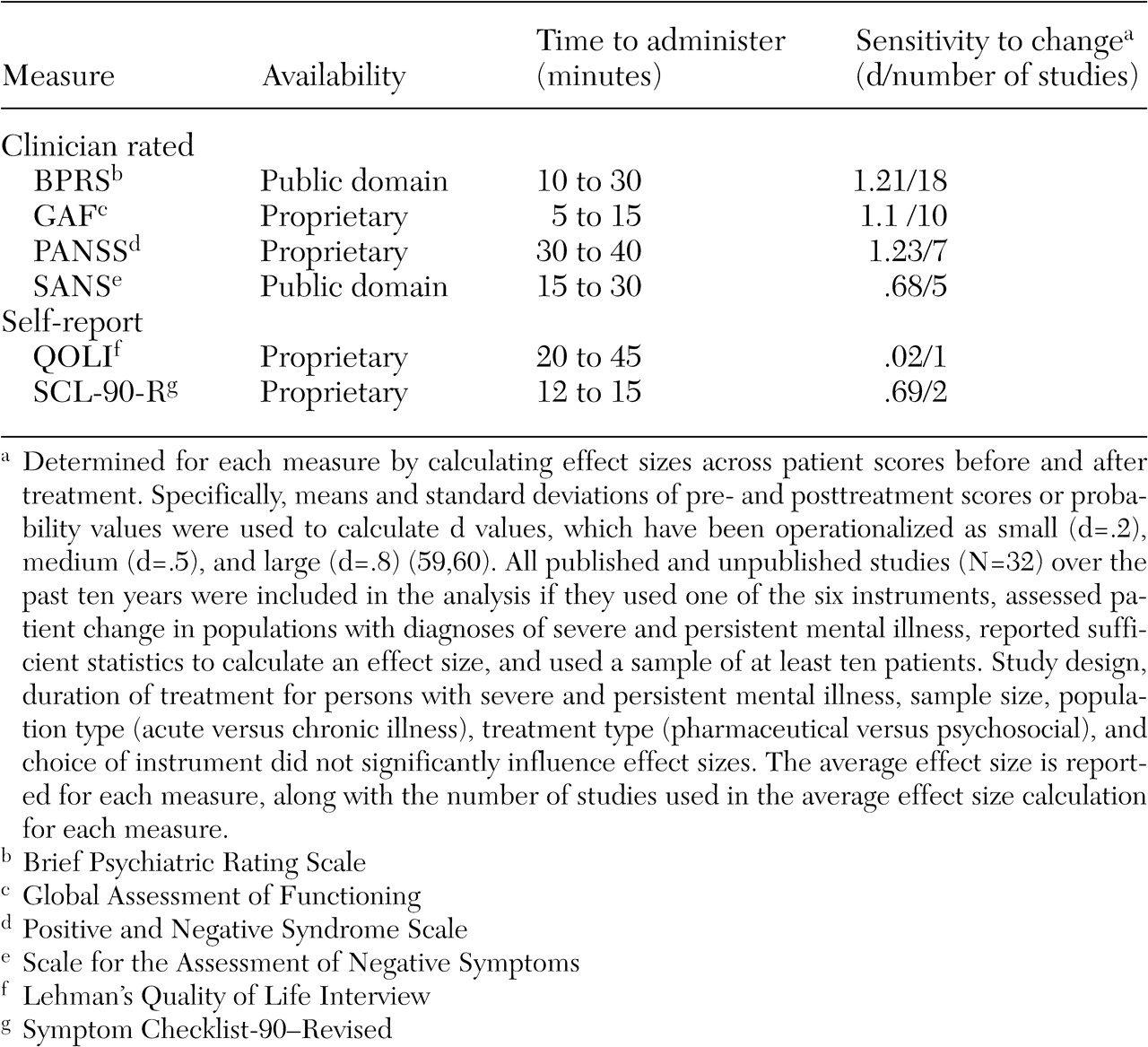
A summary of our evaluation of six of the most frequently used clinician and self-report instruments is presented in
Tables 2 and
3 (
58,
59,
60). (This summary is restricted to six instruments because of space limitations.) A brief examination of each measure and greater explication of the seven criteria follow.
BPRS. The BPRS satisfied our target population given that it was created to provide rapid assessments of psychopathology for inpatient populations. Its extensive use in the literature has produced ready-made norms for a variety of populations. There are two revisions of the original 16-item version (
49): an 18-item version (
61) and a 24-item expanded version (BPRS-E) (
62). Each version has produced four similar symptom factors—manic hostility, withdrawal-retardation (negative symptoms), thinking disturbance (positive symptoms), and depression-anxiety—that match typical patient characteristics of state psychiatric hospitals (
47).
Clinician-rated scales can provide greater consistency across patients and diagnoses than self-report measures, thereby producing more reliable systemwide evaluations (
63). However, this consistency is directly related to the quality of the training material available for ensuring adequate interrater reliability, which is a clear strength of the BPRS (
44,
57). Indeed, good to moderate interrater reliability is evident (
37,
64,
65), along with moderate test-retest reliability (
64) and good internal consistency (
65). The literature was also largely supportive of the instrument's construct and concurrent validity (
64,
66,
67,
68,
69,
70). We ranked the clinical utility of the BPRS as high, because it was normed on clinical populations, available at no cost, and very sensitive to change (average d=1.21). Its greatest shortcoming was the resource drain associated with a clinician-rated instrument, an issue addressed in the companion paper in the State Mental Health Policy column in this issue (
42).
GAF. As a standard part of the diagnostic protocol (
71), the GAF is the most widely used measure of psychiatric patient function (
33), with the extant literature providing a wealth of normative data. Introduced as a revised version of the Global Assessment Scale (
72), the GAF allows clinicians to rate global patient functioning on a single scale ranging from 1 (persistent danger of severely hurting self or others) to 100 (absence of symptoms to minimal symptoms). Research has reported interrater reliability coefficients that range from modest to excellent (
73,
74,
75,
76) as well as moderate to high concurrent validity estimates (
76,
77). From a clinical utility perspective, the GAF was viewed as comparable to the BPRS, being normed on inpatient and outpatient populations, available at no cost, very quick to administer, and very sensitive to change (d=1.10). As with the BPRS, consistency of ratings requires the implementation of rater training and periodic consistency checks.
PANSS. The PANSS was developed "as an instrument for measuring the prevalence of positive and negative syndromes in schizophrenia" (
51). It consists of the BPRS-18 (
61) plus 12 items from the Psychopathology Rating Scale (
78). Clinicians rate patients' symptoms with use of 30 items that aggregate on four scales: positive symptoms, negative symptoms, composite, and general psychopathology. Research has reported evidence of acceptable construct and concurrent validity (
79,
80), good internal consistency reliability, moderate test-retest reliability (
51), and interrater reliability coefficients that range from high to moderate (
37,
80). Clinical utility was rated lower, because the instrument is lengthier to administer, more costly to use ($32 for a set of 25 questionnaires), and normed on a narrower population. Nevertheless, the instrument appears to be very sensitive to change in our analysis (d=1.23).
SANS. The SANS was developed by Andreasen (
52,
81) as a measure of negative symptoms among patients with schizophrenia. Clinicians use 30 items that are aggregated on five subscales: affective flattening or blunting, alogia, apathy, asociality, and inattention. This instrument has adequate construct and concurrent validity coefficients (
35,
80), good internal consistency reliability (
52), moderate 24-month test-retest reliability (
82), and interrater reliability coefficients that range from moderate to high (
52,
69,
82). The instrument was ranked the lowest because of moderate clinical utility, it was normed on a single population, and it is somewhat lengthy and moderately sensitive to change (d=.68). However, it is available at no cost.
SCL-90-R. Originally designed for use with psychiatric outpatients, the SCL-90-R (
53) has enjoyed widespread use in clinical and research settings, producing a wealth of normative data. Patients respond to 90 items that are aggregated on nine symptom dimensions (somatization, obsessive-compulsivity, interpersonal sensitivity, depression, anxiety, hostility, phobic anxiety, paranoid ideation, and psychoticism) and three global scales (the global severity index, the positive symptom distress index, and the positive symptom total). Research has shown little evidence of construct validity for this instrument (
53,
83), although the instrument has shown good internal consistency, test-retest reliability (
83,
84,
85), and moderate concurrent validity with the BPRS (
86).
The SCL-90-R was viewed as having moderate clinical utility; being normed on community, outpatient, and inpatient populations; being quick to administer; and being moderately sensitive to change (d=.69). Considerations that lowered its rank were cost ($41 per 50 hand-scored answer sheets) and the fact that it is self-reported among the target population. Self-report measures require less staff time and permit consumer-focused outcome assessment, because patients are empowered to report on their symptoms and expectations about treatment (
87). Disadvantages include an insufficient clinical picture as a result of the dependence on patients' ability to accurately describe their condition, which at times is doubtful because of denial, minimization of symptoms, or responder bias (
88).
QOLI. The QOLI (
51) is a highly structured interview developed to assess current quality of life and global well-being among populations with chronic mental illness. This instrument is made up of objective and subjective questions that allow the patient to rate his or her current situation and satisfaction with life. The QOLI has good construct validity (
89,
90), moderate concurrent validity (
91), moderate test-retest reliability (
51), and high internal consistency (
92). It was ranked low on clinical utility because of its length, cost (a pay-per-use structure), and low sensitivity to change (d=.02). However, the latter was based on a single study, and norms were available for community and inpatient populations.
Step 5: selecting measures
Clinician-rated instruments clearly outnumbered self-report instruments in our analysis. Lachar and colleagues (
67) explained that clinician-rated measures have recently achieved an advantage over self-report in hospitals because of the disabling psychopathology patients now must exhibit to justify hospitalization. The impairment of newly admitted patients negatively affects patients' ability to complete even a brief self-report measure. However, the accuracy of information from clinician-completed measures must be balanced by the resource drain. The BPRS and the GAF require the least time to administer, and the BPRS, the GAF, and the PANSS appear to be equally sensitive to change, yet all instruments required mastery of training materials and demonstrated reliability to produce meaningful information about outcomes.
The team openly acknowledged the limitations of the sample, including a time frame that may have disadvantaged newer instruments—for example, the Multnomah Community Abilities Scales and Outcome Questionnaire. Furthermore, although the frequency count allowed us to easily calibrate against findings in the extant literature, it may have inadvertently excluded potentially useful instruments because of their infrequent use in our sample—for example, the Medical Outcomes Study SF-36 and the Addictions Severity Index appeared in two studies each. However, infrequent use portends unknown properties such as sensitivity to change and normative characteristics.
Three issues affected our final recommendations. First, global single-scale assessments, such as the GAF, are frequently used because they are simple to administer and provide immediate feedback (
73). However, these scales suffer limitations in accuracy as a result of combining patients' symptoms and functioning in a single rating (
93), leading some to question their accuracy with our target population (
33,
94).
Second, as with most publicly funded facilities, we have limited resources. As a mental health agency focused on improving service delivery from both an organizational and a consumer-oriented perspective (
87), we were aware of the considerable discussion about the importance and effectiveness of self-report and clinician-rated instruments (
95,
96,
97,
98). At face value, our survey suggests the BPRS and the SCL-90-R as the best clinician-rated and self-report outcome instruments. However, concerns about financial resources, administration time, staff support, staff competence, and training led to active debate. Our adoption of the BPRS led to infrastructure realignment to address these concerns, as detailed in our companion paper (
42).
Finally, our survey suggested the SCL 90-R as a self-report tool, but its use raised two concerns: meaningfulness of the outcome data given patient impairment, and cost. When patients are physically unable or unwilling, because of malingering or resistance, to complete a self-report assessment, data may be too erratic (item endorsement at both ends of the range) to facilitate meaningful interpretation. Nevertheless, we adopted an alternative self-report measure because of cost issues, and Earnshaw and colleagues (
42) detail how we dealt with data accuracy concerns.