Anxiety disorders are common; lifetime prevalence for the group of disorders is estimated to be as high as 25%
(1). They are highly comorbid with each other and with other psychiatric conditions
(2), particularly mood disorders
(3). Anxiety disorders carry a substantial burden of distress and impairment that is comparable to that of chronic “medical” disorders, such as diabetes
(4–
8). As such, their etiology has been, and continues to be, a major target of investigation.
A long history of primary studies has sought to determine whether anxiety disorders are familial and to estimate their heritability. A number of excellent, detailed reviews of the genetic epidemiology of anxiety disorders have also appeared (e.g., reference
9). Much knowledge has been amassed in this area; however, to date, there has been no attempt to summarize the information quantitatively. Therefore, a meta-analytic treatment of the data is timely, particularly as many research groups have begun to search for “anxiety genes.”
We have attempted to answer, by means of a meta-analysis of selected epidemiological studies, the following two questions for major anxiety disorders: 1) what is the magnitude of the familial aggregation of anxiety disorders? 2) what is the relative contribution of genetics and environment to their etiology?
We applied this method to the following anxiety disorders: panic disorder, generalized anxiety disorder, phobias, and obsessive-compulsive disorder (OCD). We were limited to family and twin studies, as we know of no available adoption studies of anxiety disorders.
Method
The basic goals of meta-analysis, as applied in this study to the genetic epidemiology of anxiety disorders, are 1) to determine the consistency between differing results by testing for heterogeneity across studies and 2) to combine data from multiple primary studies for the purpose of synthesizing the information, thus providing more reliable, precise, and less biased aggregate estimates of familial risk and heritability.
We performed a keyword-driven MEDLINE search to identify all potential primary studies for inclusion in our analyses. In addition, we searched the reference sections of these manuscripts and existing reviews for additional sources. We limited our analyses to studies involving adult subjects that estimated the risk in relatives for the same anxiety disorder as that diagnosed in the proband. Although some of the studies included in this analysis examined the question of familial and genetic sources of the comorbidity of anxiety disorders, this important issue is outside of the scope of this study.
We used the following inclusion criteria for the studies: 1) use of operationalized diagnostic criteria, to the exclusion of studies assessing only anxiety symptoms and older studies of anxiety neuroses; 2) systematic ascertainment of probands and relatives; 3) direct interviews with the majority of subjects, to the exclusion of family history studies; 4) diagnostic assessment of relatives performed with investigators blind to proband affection status; and 5) for family studies, inclusion of a comparison group. For some disorders, in which fewer studies were available, we relaxed the criterion for blind ascertainment of diagnosis only to increase our data pool for comparison. Many primary studies identified in the literature were rejected for failing one or more of these criteria. In particular, twin studies meeting the inclusion criteria were limited to, at most, one or two large independent samples per disorder.
Family studies may be thought of as a type of case-control study design, in which the patients are affected probands and the comparison subjects are individuals without a history of the disorder
(10). The measure of interest is the binary outcome of a relative diagnosed as affected or unaffected, which allows construction of 2×2 contingency tables of affected versus unaffected relatives of patients and comparison subjects. We reported the odds ratio as the measure of association, owing to its desirable statistical property of invariance under study design
(10) and greater familiarity to readers than, e.g., the tetrachoric correlation, which is less sensitive to prevalence
(11). In addition, stratifying by study allows one to test for homogeneity across studies by means of the Breslow-Day statistic
(12) and to calculate a summary odds ratio by means of the Mantel-Haenszel method
(13). The SAS routine proc freq
(14) was used to make these calculations. For panic disorder and OCD, for which the most data exist, we also calculated an aggregate risk by combining raw data from each of the studies.
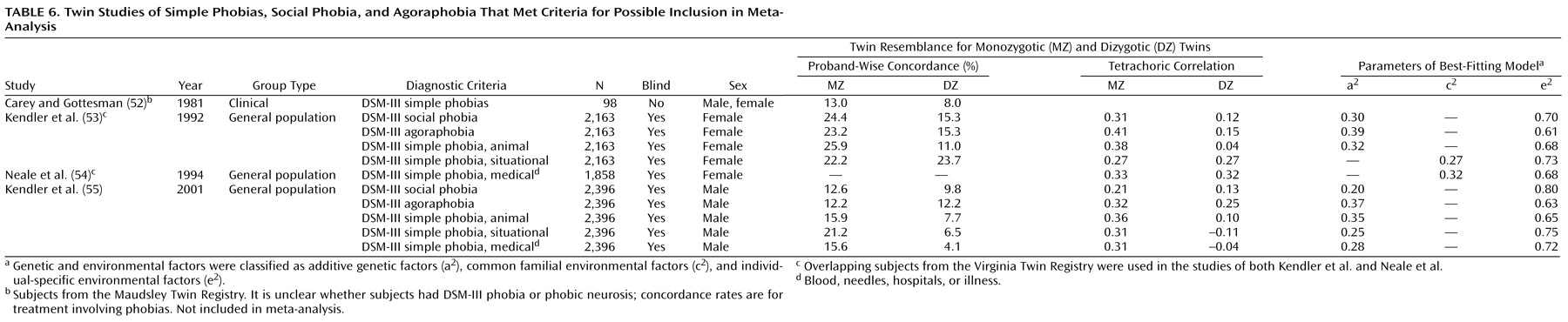
For the twin studies, we were limited by the scarcity of studies that met our inclusion criteria; only two large twin samples that met our criteria and were used to study anxiety disorders exist: the Virginia Twin Registry
(15) and the Vietnam Era Twin Registry
(16). Data from the Virginia Twin Registry have been reported regarding panic disorder, generalized anxiety disorder, and phobias; data from the Vietnam Era Twin Registry have been published on panic disorder and generalized anxiety disorder. Therefore, we attempted meta-analysis using twin data for panic disorder and generalized anxiety disorder only, but we tabulated twin data for the other disorders where it was available.
We report several measures of twin resemblance, depending on availability. The proband-wise concordance is the proportion of affected co-twins of affected index twins. The tetrachoric correlation is between the members of a twin pair regarding their liability for the disorder; it assumes an underlying continuous trait with a threshold that distinguishes between unaffected and affected twins. Structural equation modeling provides estimates of variance in liability to a disorder that are attributable to additive genetic (a
2), common familial environmental (c
2), and individual-specific environmental (e
2) factors
(17).
For panic disorder and generalized anxiety disorder, we performed structural equation modeling by combining data from the two large twin studies using the statistical package Mx
(18). To this end, we created 2×2 contingency tables of affection status for twin 1 versus twin 2 from the reported sample parameters for each study. The output of the modeling provided the fit of the model and the component estimates of variance. The fit of submodels created by placing limiting assumptions on the model (such as testing the significance of one of the variance components) was then compared to that of the full (saturated) model. Data from the Vietnam Era Twin Registry come from same-sex male twin pairs, whereas data from the Virginia Twin Registry come from same-sex female twins for panic disorder and male-male, female-female, and opposite-sex twin pairs in the most recent assessment of generalized anxiety disorder. Therefore, the most saturated models allowed for differing proportions of genetic and environmental variance between men and women, whereas the submodels tested the hypothesis that these were the same for the two genders. In setting up the model, significant differences in prevalence in the various groups required that different thresholds be assigned.
Finally, for panic disorder and generalized anxiety disorder, we attempted to perform an overall structural equation modeling of the combined twin and family data. In comparison to the population-based twin data, data from all of the family studies were from clinically ascertained probands. Therefore, some restrictive assumptions had to be made in order to combine them. Owing to differing prevalence estimates among the family studies that were obtained by use of unequal comparison groups, a threshold for each family study was not calculated from the sample characteristics as it was for the twin data, but, rather, it was assigned from a base prevalence rate obtained from National Comorbidity Survey data
(1). In addition, because the family study data were not reported separately by gender or type of relative, we had to make the rather broad assumption that all of the first-degree relatives in these studies could be modeled as if they had the same genetic and environmental correlations as did their siblings (or dizygotic twins). We tested the validity of this assumption by including a special twin environmental parameter that differentiated between dizygotic resemblance in twin pairs and all first-degree relatives in the family studies. We also had to test the hypothesis that model parameters from clinical and community samples could be equated to obtain aggregate estimates. Since all of the family studies used clinical study groups and the larger twin studies were community-based, it was not possible to test these last two assumptions separately. For several studies, partially or wholly overlapping samples were studied in more than one report. In most cases, we chose the studies that contained the largest sample sizes or the most recent results.