We examine the work of Fisher and Greenberg and their colleagues
(1–
6), as well as that of Antonuccio et al.
(7,
8), Moncrieff et al.
(9), and Kirsch and Sapirstein
(10), all of whom present basically similar viewpoints. The reports of Fisher and Greenberg and their colleagues
(1–
6) will be examined more closely, since they are the most extensive contributors. Their work has been broadly referred to in the general media
(11–
19) and has appeared in various clinical discussions
(20–
22).
In broad outline, their position has three anchors, the first of which is that placebo treatment alone results in clinically significant improvement. Their second point is that by and large antidepressants are no better than placebo and that their illusory superiority hinges on methodologically flawed studies and biased clinical evaluations
(1–
5). In particular, it is asserted that the integrity of the placebo-controlled, double-blind randomized trial is undermined by a penetrable blind that results in biased ratings by drug-favoring clinicians
(4). They assert that clinicians’ guesses about treatment type exceed chance because clues from side effects of the active drug are poorly camouflaged by inactive placebo
(4). This penetration of the double-blind permits more favorable rating of patients presumed to be on active drug. As a corollary to these assumptions, it is argued that active placebo would reduce rater bias
(2). The third point of Fisher and Greenberg et al. is that psychotherapy is as effective as antidepressants in both the acute and maintenance treatment of depression
(3). Overall, they conclude that valid evidence for antidepressant efficacy is lacking
(5).
This perspective continues to resurface in the media, as seen in a recent
New York Times op-ed column
(16). In it, the columnist argues that even the slight advantage reported for antidepressants over placebo “may be illusory, according to researchers like Roger Greenberg, a psychologist….Because all psychiatric drugs have side effects….both patients and researchers invariably see through the double blind, according to Dr. Greenberg.” Further evidence that this position is not confined to fringe faction coverage comes from a recent “News Focus” published in
Science: “It is suggested that there are challenges to the scientific basis of much of the multibillion dollar market for antidepressant drugs”
(23).
While most psychiatrists have a balanced view regarding the advantages and limitations of antidepressants, they may be unfamiliar with the details of the research literature supporting antidepressant efficacy as well as the basis for the criticisms leveled against it. It is likely that patients will ask questions about proposed antidepressant treatment, especially when they read negative reports in authoritative sources like The New York Times. This review may be helpful in facilitating informed discussions of the pros and cons of antidepressant treatment and questions about true drug efficacy.
ANTIDEPRESSANT EFFICACY: WHAT IS THE EVIDENCE?
The psychiatric research literature suggests that antidepressants are effective for 50%–60% of patients with DSM-IV unipolar depression and that placebo treatment is effective for 20%–30%, with higher placebo response rates for patients with mild depression
(25). In a comprehensive 1999 study prepared for the Agency for Health Care Policy and Research
(26), an expert multidisciplinary panel reviewed more than 80 randomized, controlled trials of marketed antidepressants that had lasted at least 6 weeks, including those of the newer antidepressant drugs. Outcome was based on a modified intention-to-treat analysis (number of trial completers rated as improved divided by total number of subjects initially randomized). This intention-to-treat analysis assumes that all dropouts are treatment failures, thus giving a conservative lower limit to estimates of treatment utility. In this review, the reported response rates were 50% for antidepressants and 32% for placebo among patients with major depression. These rates are similar to those cited by Thase
(25).
In a meta-analysis of treatment with tricyclics for late-life depression
(27), a 7–9-point improvement in score on the Hamilton Depression Rating Scale over that of placebo was observed, which approximates a 30% difference in a categorical global measure. These overviews approximate the global advantage of imipramine versus placebo reported by Klerman and Cole
(28) more than 30 years earlier. They rated 65% of 550 drug-treated and 31% of 459 placebo-treated patients as having responded. Indeed, this is approximately the position cited by Fisher and Greenberg
(6), who say that “proponents of medication usually conclude that about one-third of patients do not show improvement with drug treatment, one third display improvement with placebos, while the remaining third are believed to show improvements with medications that would not have been achieved with placebo” (pp. 118–119).
The disagreement between proponents of medication and the antidepressant skeptics concerns the validity of these findings. The skeptics suggest that without clinician bias, antidepressants would appear about as effective as placebos. The skeptics cite three bodies of evidence: 1) “blinder” studies in which an experimental drug is compared to both placebo treatment and a so-called “standard” drug, where the standard drug is no more effective than placebo; 2) studies in which clinician and patient ratings of perceived outcomes differ
(5); and 3) studies in which inert rather than active placebos are used, compromising the blind—as suggested by raters’ treatment guesses exceeding chance—and thus inflating the drug effect
(3,
4).
Blinder Studies
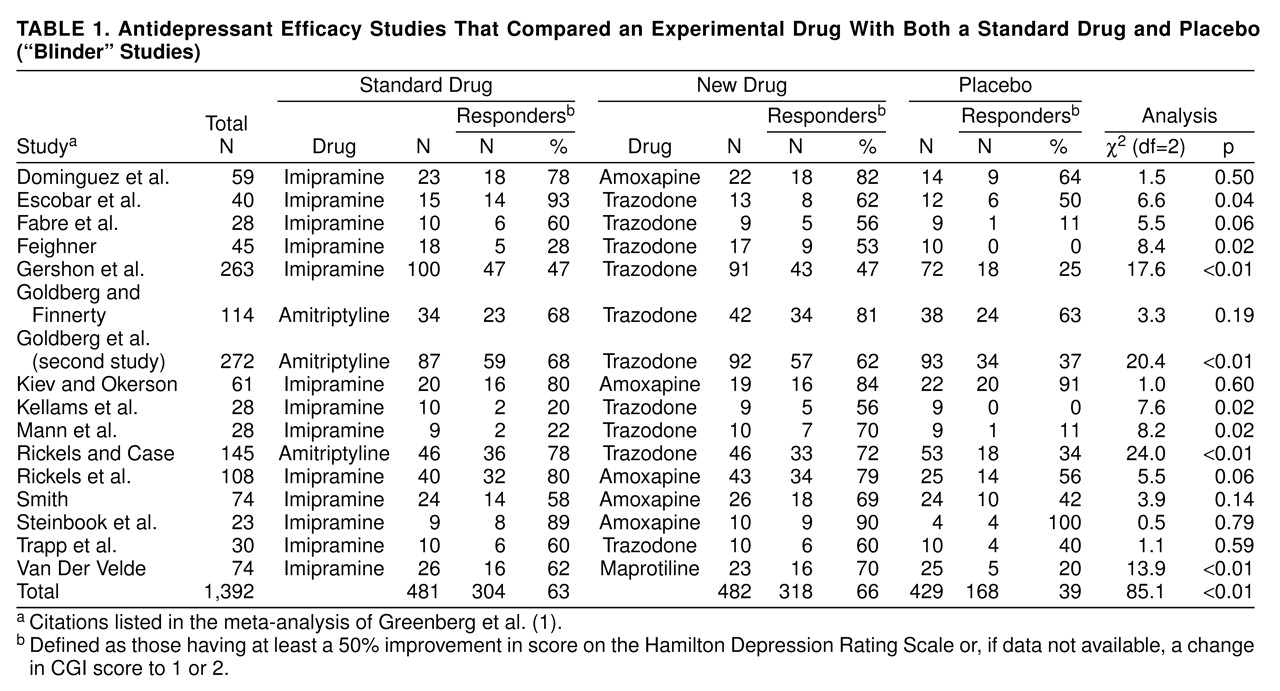
This term refers to a three-armed study with an experimental drug, standard drug, and placebo. Standard drugs (e.g., imipramine and amitriptyline) are so identified when they have been widely studied and used, and their efficacy is considered clearly established. It has been suggested that in blinder studies, “there is somewhat less vested interest in establishing the efficacy of the standard drugs”
(1, p. 664). Consequently, the response rate of the standard drug in this setting is claimed to be a more valid estimate of its real effect than would be observed in two-armed studies in which investigator enthusiasm may engender bias. In their 1989 book
(2), Greenberg and Fisher reviewed 16 blinder studies, while in their 1992 article
(1), 22 studies were cited. Our analysis examines the original 16 studies because the six additional blinder studies
(29–
34) were uninterpretable, since two had no placebo group, one had no outcome data, and three lasted only 21 days (a duration of 6 weeks is needed to see specific drug effects [
35,
36]). The 16 studies discussed by Fisher and Greenberg in their meta-analysis are outlined in
table 1.
In their meta-analysis
(1), Greenberg et al. calculated the effect sizes of the blinder studies and stated that they were “two to four times less than those previously reported” (p. 666), and that 66% of the studies showed no difference between standard drug and placebo. The effect size refers to the difference in the effectiveness of a treatment of interest minus that of a control condition (standard drug or placebo).
Our review of their meta-analysis indicates that in eight of the 16 studies, medication was statistically superior to placebo (p≤0.05) and approached significance (p=0.06) in two other studies (
table 1). In 14 of 16 studies, a higher percentage of subjects given the standard medication than of those given placebo responded. In the two aberrant cases, placebo response rates were 91% and 100%, so no treatment could be superior. A sign test yields p=0.004, two-tailed, for the superiority of the standard drug over placebo. Results of a Mantel-Haenszel chi-square analysis
(37) that combined standard drug and placebo response data from all studies in
table 1) and used a 50% decrease in Hamilton depression scale score (or, if unavailable, a CGI of 1 or 2) as the criterion for treatment response were highly significant (χ
2=68.4, df=1, p≤0.0001). A consistency test did not suggest significant interstudy differences (χ
2=2.9, df=1, n.s.). Contrary to the blinder studies hypothesis, the effect size for the standard drugs (26%, 95% confidence interval [CI]=0.20–0.32) was equivalent to that of the new drugs (27%, 95% CI=0.21–0.33). The effect sizes of the standard and new drugs were not “one-half to one-quarter of those previously reported” as Fisher and Greenberg stated
(1), and their equivalency fails to support the suggestion that this paradigm offers a more valid assessment of the standard drug.
Their thesis has another basic flaw. Pharmaceutical companies sponsored the 16 blinder studies to obtain approval from the Food and Drug Administration (FDA) for amoxapine, trazodone, and maprotiline. FDA approval requires evidence that the candidate drug is superior to placebo. Inclusion of a standard drug provides information about the new drug’s relative efficacy, while differences between standard drug and placebo outcome help to validate the diagnostic specificity of the sample studied. A study that fails to demonstrate a difference between standard drug and placebo outcome would raise questions about the sample’s diagnostic composition and thus would be considered by the FDA to be a “failed study”
(38,
39). If the standard drug actually was ineffective, having approximated placebo in 66% of the studies, sample appropriateness would have been suspect, and the FDA would have withheld drug approval. Leber has referred to “the importance of internal controls to demonstrate what we now call ‘assay sensitivity’…to deal with sampling variation”
(38,
39). However, the primary point is that the conclusion of Greenberg et al., that standard drugs have minimal benefit, fails to gain support after reanalysis of the blinder studies (
table 1).
Doctor-Patient Differences in Perceived Outcomes
The antidepressant skeptics also propose that patient self-ratings, because of a greater freedom from drug bias, are more valid than clinician outcome ratings. We examined the empirical basis for this conclusion and find it flawed.
In their 1992 article
(1), Greenberg et al. cited a meta-analysis by Lambert et al.
(40) that included studies with both a self-rating scale and a clinician-rated scale in which self-reports were said to provide “a significantly smaller effect size than did clinician rating scales” (p. 665). However, Lambert and colleagues had cautioned that the self- and doctor-rated scales may actually measure different aspects of depression “and therefore should not be expected to yield comparable results.” These and other prudent remarks were not cited by Greenberg et al. in their critique.
Concerns about patient-clinician rating scale discrepancies antedate Lambert. Kellner et al.
(41) noted that “observer rating scales may be more sensitive in discriminating drug and placebo than self-rating scales.”
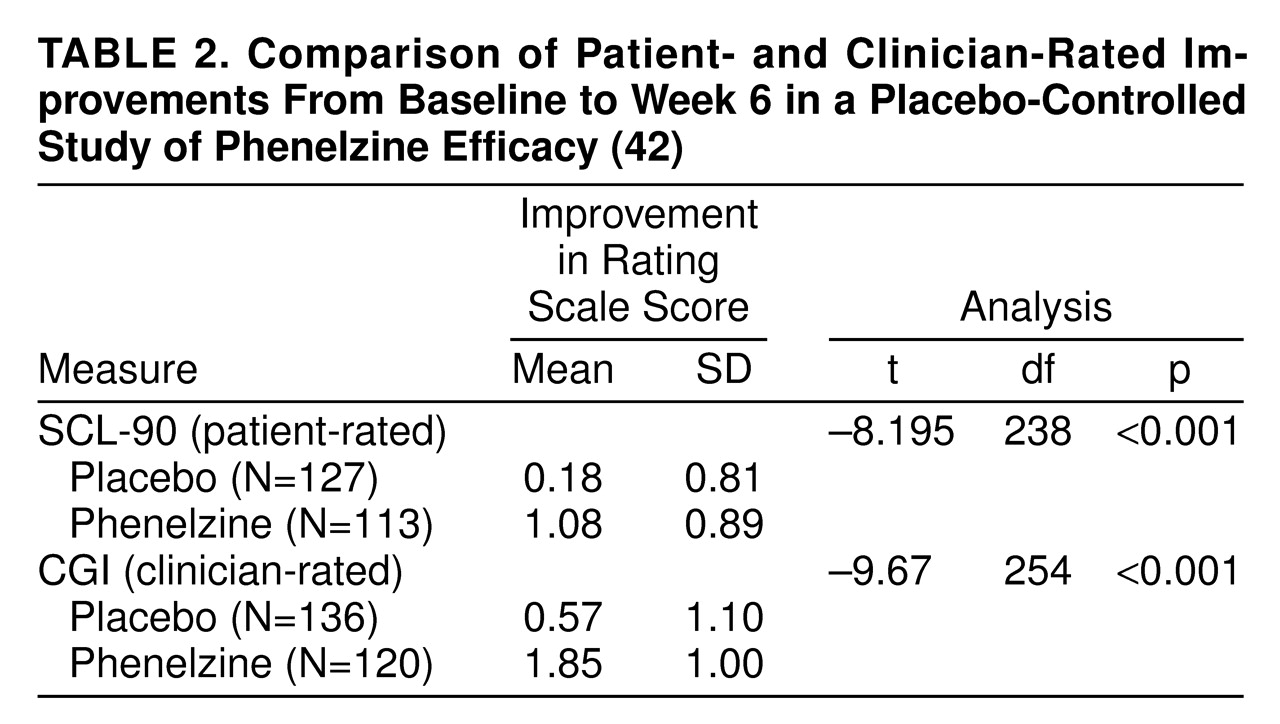
Do patients who clinicians consider improved consider themselves less depressed? Since self-ratings were rarely included in the 16 blinder studies, we analyzed data from our own trials to contrast magnitude of change derived from patient- and clinician-rated scales. In one data set, patients were randomly assigned to placebo (N=135) or phenelzine (N=120) in a 6-week trial; scores from the clinician-rated Clinical Global Impression and the patient-rated SCL-90 depression subscale were compared
(42). Paired t tests were used to estimate the difference in magnitude of change between baseline and week 6 assessments for the two measures. As shown in
table 2, both clinician and patient ratings showed significantly greater improvement for phenelzine-treated patients over placebo. The correlations between doctor and patient ratings at week 6 within each treatment group were quite high (placebo group: r=0.70, df=126, p<0.001; phenelzine group: r=0.78, df=113, p<0.001). With respect to effect size, on the SCL-90 depression subscale, the active drug versus placebo effect size was 0.94. The effect size based on the clinician-rated Clinical Global Impressions change scale was 1.04. Both are extremely robust; anything above 0.80 is considered a strong effect
(43). Thus, evidence of a disparity in which drug treatment was only favored according to clinician ratings and not patient self-ratings of improvement was not demonstrated.
Inert Versus Active Placebos
Several groups have suggested that the use of inert placebos is inadequate, asserting that drug side effects enable identification of active drug recipients
(3,
9,
44). The rationale for giving an active placebo would be to create drug-mimicking side effects to improve the blind, thus increasing the placebo response rate so that it approximates drug response rate. This would suggest that observed drug benefit is just placebo effect plus effect stemming from patient or clinician attribution. Only a higher response rate with active placebo, compared to rates with inert placebos, would be consistent with this thesis.
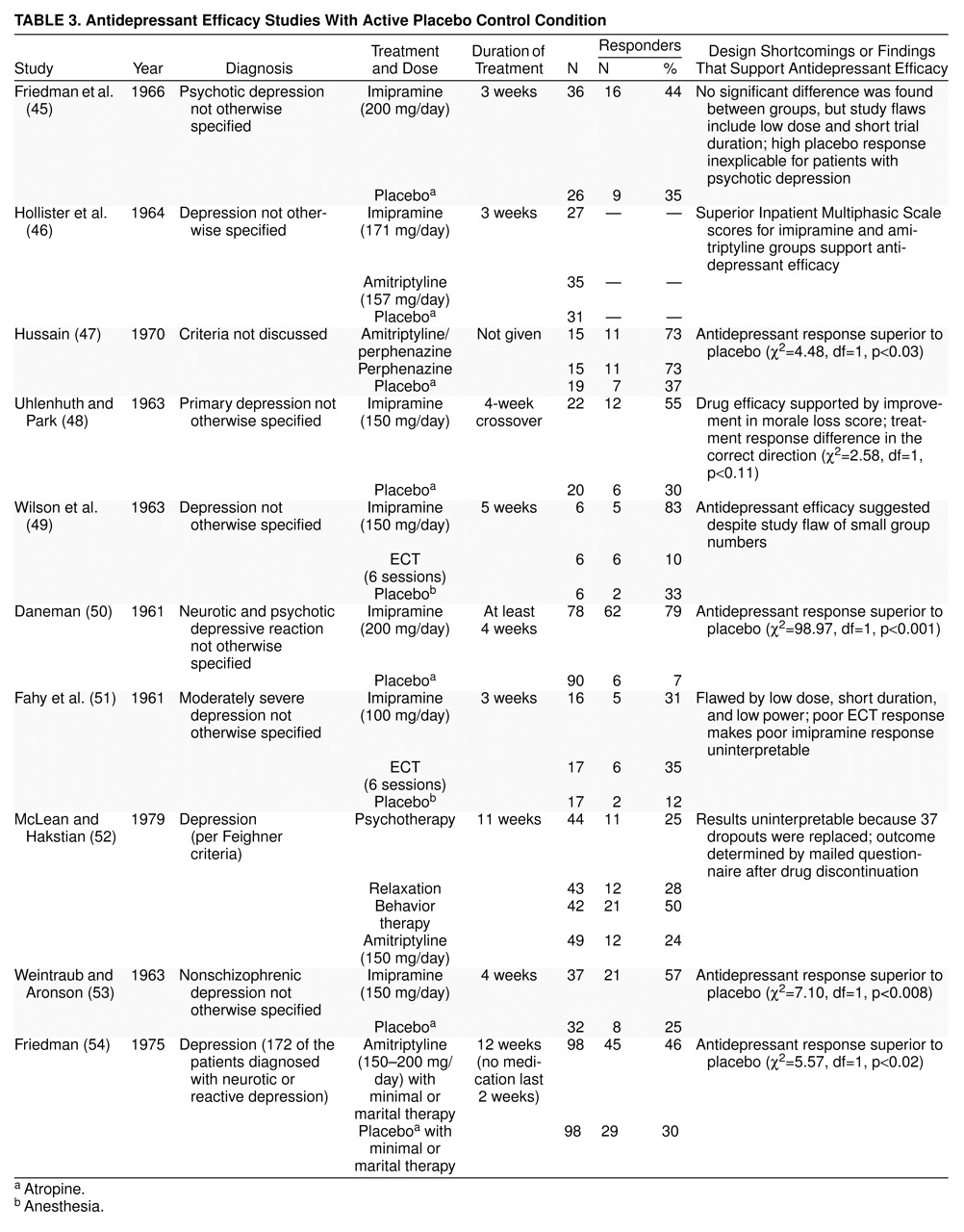
Thomson reviewed 68 double-blind studies of tricyclics that used an inert placebo and seven that used an active placebo
(44). He found drug efficacy was demonstrated in 59% of studies that employed inert placebo, but only 14% of those that used active placebo (χ
2=5.08, df=1, p=0.02). This appears to demonstrate that in the presence of a side-effect-inducing control condition, placebo cannot be discriminated from drug, thus affirming the null hypothesis. (Thomson’s review identified six studies that used active placebo but counted two treatment groups in one study as if independent [45–50].) In addition to the studies Thompson cited, four additional studies are discussed in the more recent “active placebo” reviews
(3,
9). These 10 studies are outlined in
table 3 (45–
54).
Does the use of active placebo increase the placebo response rate? This is not the case. After pooling data from those studies in which a judgment could be made about the proportion of responders, it was found that 22% of patients (N=69 of 308) given active placebos were rated as responders. To adopt a conservative stance, one outlier study
(50) with a low placebo response rate of 7% (N=6 of 90) was eliminated because its placebo response rate was unusually low (typical placebo response rates in studies of depressed outpatients are 25%–35%). Even after removing this possibly aberrant placebo group, the aggregate response rate was 29% (N=63 of 218), typical of an inactive placebo. The active placebo theory gains no support from these data.
Closer scrutiny suggests that the “failure” of these 10 early studies to find typical drug-placebo differences is attributable to design errors that characterize studies done during psychopharmacology’s infancy. Eight of the 10 studies had at least one of four types of methodological weaknesses: inadequate sample size, inadequate dose, inadequate duration, and diagnostic heterogeneity. The flaws in medication prescription that characterize these studies are outlined in
table 3. In fact, in spite of design measurement and power problems, six of these 10 studies still suggested that antidepressants are more effective than active placebo.
In summary, these reviews failed to note that the active placebo response rate fell easily within the rate observed for inactive placebo, and the reviewers relied on pioneer studies, the historical context of which limits them
(3,
9,
44).
Double-Blind Guesses
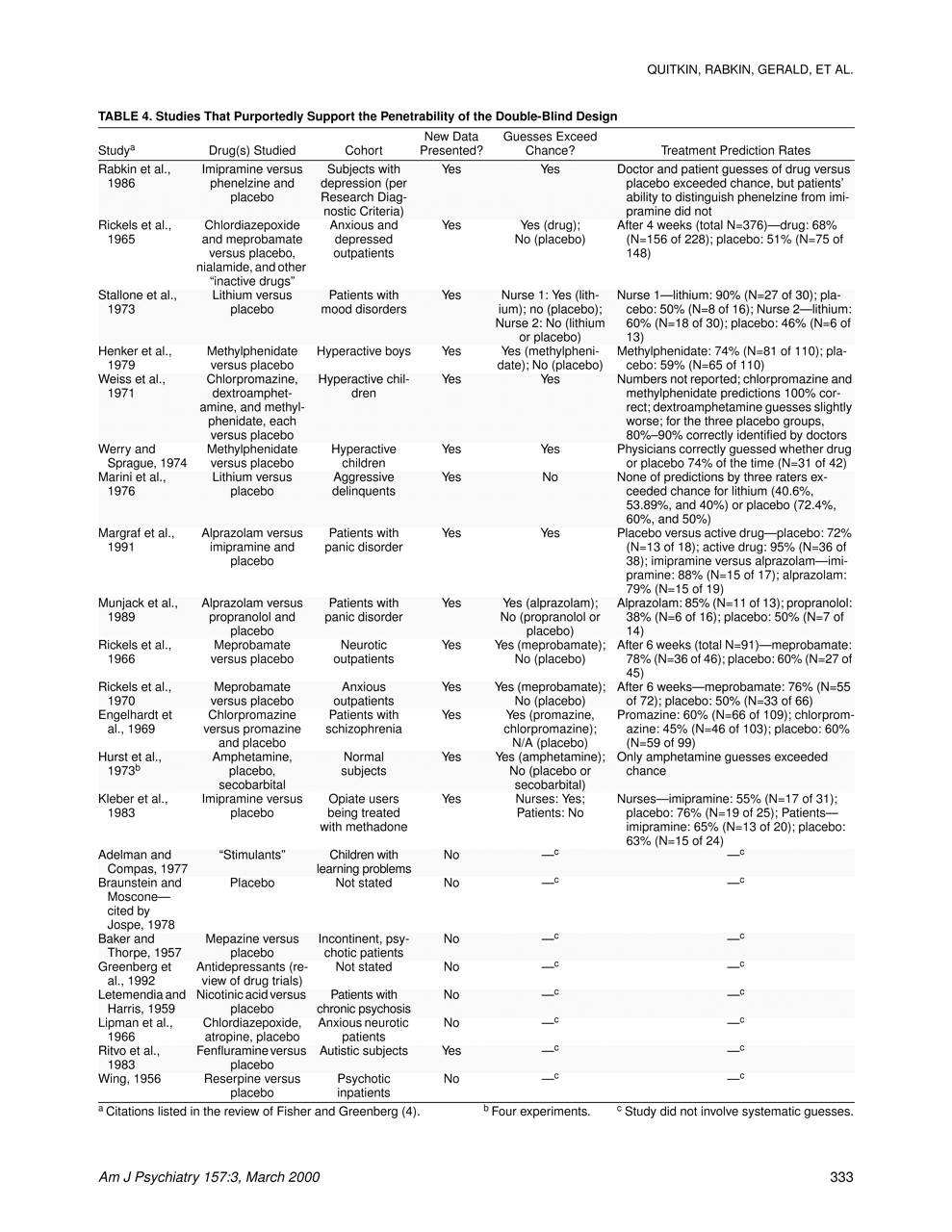
As further evidence that antidepressant trials are invalid, reference has been made to a study done by our group at Columbia, in which blind raters’ guesses exceeded chance
(55). In one review of this area, 22 other studies are cited in which it is suggested that treatment guesses collected before breaking the study blind exceed chance
(4). This evidence is offered to show that the side effects of the active drug were responsible for this breaking the blind. The possibility that clinical outcome also contributes to guessing correctly is not considered. Clinicians are likely to assume that responders were getting active drug. So if 60% respond on drug and 30% on placebo, merely guessing drug for all responders and placebo for all nonresponders would exceed the chance expectation for correct guesses.
We examined the original sources of the 22 studies cited; only eight were found to include actual clinician guesses (listed in
table 4). Others either lacked original data or gave anecdotal impressions. Furthermore, only three of these 22 studies included antidepressant medications, and most of the drugs (e.g., chlorpromazine, meprobamate) today would not be used to treat depression. The relevance of these studies is thus doubtful, particularly when coupled with the aforementioned low response rate noted with active placebo.
ARE PSYCHOSOCIAL TREATMENTS MORE EFFECTIVE THAN DRUGS?
Several reports have suggested that psychotherapy is superior to drugs in treating depression
(3,
7,
8,
10). In one review it was asserted that “depression specific psychotherapies more often than not eclipsed the results obtained with drugs”
(3). Eight trials that compared a specified type of psychotherapy (for depression) to antidepressants, reported in seven studies, were included in this review. Three of these trials indicated that psychotherapy was equivalent to medication in fostering improvement
(56–
58), and five indicated that psychotherapy was superior to the drug in promoting substantial change
(56,
58–
61). The other reviews of this area
(7,
8,
10) used a somewhat different approach, but their conclusions are similar. Space limitations require us to focus on one review, but similar problems are noted in the others and have previously been discussed
(62).
Several points should be noted. First is the need for a “psychotherapy placebo.” A necessary first step before conducting treatment efficacy comparisons is to demonstrate a treatment’s superiority to placebo. Does the treatment produce benefits over and above nonspecific factors such as coming for treatment, having a professional ally, etc.? In medication evaluation, the comparison placebo treatment plays this role. There has been substantial controversy over the appropriate parallel for the evaluation of psychotherapy. Klein
(62) has critically assessed the logic of using pill placebo-case management as an adequate control for both medication and psychotherapy.
The relationship between medication and psychotherapy with regard to demonstration of specific benefit is not symmetrical. Standard medications have been shown to be superior to placebo under appropriately controlled circumstances. However, such systematic assessment of specific value is only a recent feature of psychotherapy studies.
Studies that contrast psychotherapy and a standard drug are analogous to studies of a standard drug versus a putatively active new medication. A simple direct comparison of the two medications is not adequate. Even if the two treatments were equivalent, the new treatment’s efficacy would not be established. Without calibrating the placebo response rate in any sample, two treatments might appear equally effective when, in fact, neither was having an effect.
An equally relevant criticism is that the data cited do not actually show that psychotherapy was superior to pharmacotherapy. Studies by Blackburn et al.
(56) and Rush et al.
(63) were cited as examples of psychotherapy’s superiority. Blackburn et al.
(56) studied two patient groups: hospital-based outpatients and general practice patients, some of whom had been symptomatic for only 2 weeks. Cognitive therapy, drug of choice (amitriptyline or clomipramine), or the combination was administered. All treatment-response differences were observed in the general practice group. Treatment responses in the hospital-based groups were equivalent. Blackburn et al. noted that “poor compliance” or dysphoria associated with adverse “social and economic conditions” seen in general practice may have lowered the medication response in the primary care group
(56); however, these cautionary remarks were not mentioned.
Rush et al.
(63) contrasted cognitive therapy with imipramine during a 12-visit trial. Before discontinuing imipramine, treatment effects were equal. After imipramine discontinuation, a subsequent evaluation noted cognitive therapy’s superior outcome. Rush et al.
(63) cautioned, “a question may be raised as to whether the level of improvement of some of the pharmacotherapy patients reflected a reduction of drug dosage.” In the Blackburn and Rush studies, lack of a placebo group and other design problems noted by the investigators themselves make psychotherapy and pharmacotherapy contrasts less informative.
Antonuccio et al.
(7) cited a meta-analysis by Robinson et al.
(64) and noted psychotherapy had a statistically significant mean effect size that was 0.13 larger than that for drug therapy. The cautionary statement by Robinson et al. (“after investigator allegiance had been controlled...the advantage of psychotherapy...was no longer statistically significant” [p. 39]) was included only as an afterthought.
The original report of the NIMH collaborative study of depression is cited as another example of the apparent equivalence of medication and two types of psychotherapy: interpersonal therapy and cognitive behavior therapy
(65). However, reanalysis of these data indicated imipramine’s superiority for severely depressed patients, compared to the psychotherapy and placebo conditions
(66,
67). For the most severely ill group, interpersonal therapy was superior to placebo on only one measure, while cognitive behavior therapy was indistinguishable from both interpersonal therapy and placebo.
Post hoc stratification by diagnosis was performed in another reanalysis
(68,
69). Patients with atypical depression responded poorly to imipramine (at a rate indistinguishable from placebo). Our group and others have previously documented the mediocre effect of imipramine for this diagnostic group
(42). Cognitive behavior therapy was superior to imipramine (interpersonal therapy showed trend superiority to imipramine [p=0.08]). Underlining the relevance of a placebo control for drug-psychotherapy studies is the fact that neither interpersonal therapy nor cognitive behavior therapy were superior to placebo for patients with atypical depression. In the nonatypical patients, imipramine treatment was superior to both placebo and cognitive behavior therapy but not interpersonal therapy (which was superior to placebo). Patients with atypical depression account for 25%–40% of outpatient cases of depression
(70). Since previous psychotherapy-drug studies did not consider the poor tricyclic response of patients with atypical depression, this may account for the mediocre outcome of medications in some of the studies.
The issue of “investigator allegiance” to a particular method of psychotherapy is receiving increasing attention in the psychotherapy literature. The concept is equivalent to the problem of “clinician bias” in drug research. A team of investigators led by Luborsky et al.
(71) examined 24 psychotherapy studies that included 29 comparisons. Study criteria for this review included clear-cut diagnosis and randomization, but was unique in that a rating of therapeutic allegiance was also included. They concluded that “the results both of past analyses and the present one imply that the researcher’s allegiance tends to be strongly associated with the differential outcomes of the treatments...the combination of the allegiance measures shows a very large association with treatment outcomes (r=0.85!)” (p. 103).
In an accompanying editorial, Shaw
(72) stated that “their original research leaves me with few questions that, indeed, researchers are biased or at least potentially biased in their impact on the results of their own trials” (p. 131). In a separate commentary, Hollon
(73) noted that “allegiance effects are ubiquitous in treatment outcome research” (p. 107). The possibility of bias affecting placebo-controlled medication trials is real, but in psychotherapy research there is not any blind; therefore, allegiance effects (and the resulting potential for bias) may be even a greater problem.
Another consideration concerns drug augmentation. In clinical practice if drug-treated patients have not improved after 6–8 weeks, thyroid hormone, amphetamine, lithium, or an additional antidepressant would be added to the initial regimen
(74). This augmented medication trial, which would be completed in the time required for a single psychotherapy trial, is likely to increase the proportion of responders by another 15%–20%
(74). There is no equivalent to such augmentation for nonpharmacologic treatment except, of course, the addition of drug treatment.
CONCLUSIONS
Our examination of the original source material cited by antidepressant skeptics suggests that these critiques of the antidepressant literature are largely unsubstantiated. Findings from antidepressant research are usually valid; these medications are often specifically useful.
We do not dismiss the likelihood of biased ratings. It is possible that a reasonable scientist, in evaluating an ambiguous clinical outcome, may use different criteria when assessing patients guessed to be taking drug or placebo. That distinct side effect profiles may permit some piercing of the double blind is probable, but this does not appear to invalidate results. Davis et al.
(75) reviewed the effect sizes of a variety of medical treatments. Their meta-analysis suggested that drugs used in psychiatry were two to three times more effective than placebo and as effective as penicillin for pneumococcal pneumonia or streptomycin for tuberculosis.
Investigators of all allegiances should not be complacent about the possibility of bias affecting their studies. However, our review of this antidepressant-critical research suggests that overall, these critiques may be allegiance driven. Cautionary remarks that were included in the original sources frequently were omitted, and doubtful studies with design shortcomings were portrayed as definitive. Misleading information about the role of antidepressants and their relative benefit compared to psychotherapy may have a deleterious public health impact. Patients and therapists may assume medication is unnecessary. The potentially serious public health implications of this type of reporting were seen when patients, after the lay press erroneously discussed a possible link between fluoxetine and suicide, generalized their fear and avoidance to other antidepressants
(76).
Another issue raised by this review is underlined by the apparent discrepancy between the primary sources we reviewed and the presentation of these data. Peer reviews more easily identify errors of commission than omission of data or absence of a fair representation of alternative hypotheses. The peer-reviewed articles included in this article had errors that were apparently missed by the original journal reviewers. A more balanced view of controversial areas, particularly where allegiance may color interpretation, will occur if articles in these areas are accompanied by critiques and rebuttals by adherents to other positions.
Rather than repeatedly examining old studies for their flaws and strengths, it would be constructive to move to the next stage of research, including the formation of research consortia and the conduct of “mega-trials” with investigators of varied theoretical orientations. In order to clarify relative efficacy in drug-psychotherapy contrasts, minimal requirements should include intrastudy placebo calibration, the participation of expert psychopharmacologists and psychotherapists, and rigorous experimental design and measurement. Multisite studies done by mutually monitored collaborating investigators, some with allegiance to psychotherapy and others to pharmacotherapy, that result in findings repeated at different sites would be most convincing. Such large-scale research programs, as Andrews
(77) has noted, are relatively “immune to the methodological and political hazards that can beset small randomized, controlled trials and meta-analyses.” The empirical findings thus generated would provide a firm basis for development and implementation of clinical guidelines.