The Substance Abuse and Mental Health Services Administration (SAMHSA) estimated that in 2014 less than half of the 43.6 million adults with a mental illness received mental health services (
1). National guidelines recommend universal depression screening along with adequate systems for accurate diagnosis, treatment, and follow-up (
2). However, many adults diagnosed as having depression do not receive treatment (
3–
5), despite the availability of safe and effective psychological (
6) and pharmacological (
7) treatments. The financial cost of nonengagement is high (
8,
9), and antidepressant use among patients with mental illness is associated with reduced mortality and rate of completed suicide (
10). Taken together, recent data from the World Health Organization (WHO) suggest that only 16.5% of individuals with major depressive disorder each year receive minimally adequate treatment (
11).
Thornicroft and colleagues (
11) described the broad flow of depressed patients through the acute care pathway. After a diagnosis, 57% of patients reported needing treatment, 71% of these made at least one visit (initiated treatment), and 41% of these received treatment that met at least minimal standards (
11). Ethnographic and experimental research into the second step revealed barriers to initiating treatment (
9,
12–
17). Practical barriers included perceived or real inability to pay (or lack of insurance coverage), lack of child care or transport, and not knowing where to go (
9,
16–
18). Psychological barriers included stigmatization of depression, doubts that treatment is effective, or concerns that others may find out (
14,
16,
17,
19–
21), and these barriers were particularly prevalent among women and people of color (
5,
16,
17,
19,
20). Culture-specific nuances, such as the somatization of depressive symptoms among women of color (
17,
22), can also complicate the detection of depression and the uptake of treatment. This had led groups to emphasize the need for tailoring interventions to specific patient strata (
16,
17,
20,
21,
23,
24).
What can be done to continue to develop this line of research? Other areas of medicine have highlighted the importance of “real-time” preemptive efforts to avoid unwanted outcomes, such as predischarge care planning for patients at high risk of readmission (
25). Behavioral economic research has illustrated the utility of “nudges”—aspects of choice architectures that alter behavior in a desired way without restricting options or altering economic incentives. Patients fall into statistically reliable groups on the basis of their reasons for not initiating treatment (
15), and certain patient groups may benefit from tailored interventions to improve treatment uptake (
16,
17). Therefore, one application of this concept could be to direct preemptive efforts toward patients at risk of not initiating treatment (and to determine why they might not). This would require analytic strategies to identify barriers at the patient rather than the group level. In such situations, machine learning is useful for extracting patterns from a wide range of characteristics that are statistically related to an outcome of interest (
26,
27).
The study’s goal was to develop a tool to estimate which individual patients might not initiate treatment among those who acknowledge a need. First, we applied machine learning to a large volume of retrospective patient-related information to develop a case identification algorithm that could be applied in a physician’s waiting room. Second, among patients who endorsed needing treatment but not getting it, we used self-reported variables to predict patients’ specific reasons for not getting treatment. Third, to make machine learning results more interpretable for clinicians, we developed an open-source software library for calculating and illustrating exactly how each participant’s characteristics contributed to each prediction by the algorithm. These real-time methods for identifying patients at risk of not initiating treatment may help health systems improve treatment uptake before patients decide not to engage in behavioral health care.
Methods
We used data from the National Survey on Drug Use and Health (NSDUH), conducted annually by SAMHSA, which provides nationally representative data on substance abuse and mental illness in the U.S. civilian, noninstitutionalized population ages ≥12. In brief, participants complete the survey at home on a computer provided by the interviewer, largely without assistance, and are compensated $30 for approximately one hour. NSDUH uses a state-based design, with an independent, multistage area probability sample within each state and the District of Columbia. There is no planned overlap of sample dwelling units or residents. Weighted response rates have ranged between 71.2% (2014) and 75.7% (2009). Institutional review board approval and informed consent were not needed because this was a secondary analysis of public data.
Sample Selection and Outcome Definition
We combined individual participant data from public use files between 2008 and 2014 (N=391,753), excluding individuals under age 18 (N=121,526) and retaining adults who reported that in the past year a doctor had told them that they had depression (N=20,829). The primary outcome was a participant’s self-reported (binary) response to the question, “During the past 12 months, was there any time when you needed mental health treatment or counseling for yourself but didn’t get it?” We excluded 44 participants who did not respond. Of these 20,785 participants, 6,271 (30%) indicated that they did not get the treatment or counseling that they needed. These participants were then asked, “Which of these statements explains why you did not get the mental health treatment or counseling you needed?” with 14 specific options and one option for “other” reasons. [A CONSORT diagram is included in an online supplement to this article.] Participants were allowed to choose more than one option, and 46.2% of individuals did so. For these analyses, we excluded 61 participants (.98%) who did not give any reason.
Predictor Selection
We preselected a small number of participant-level characteristics that were surveyed consistently from 2008 to 2014, have been identified in prior epidemiological studies as relevant to depression (
28), and could be self-reported via Web-based assessment. These included sociodemographic characteristics, information about current behavioral health and suicidal thoughts, and a brief medical history. We used categorical single imputation whenever participants were missing a value for a predictor variable (<1% for most variables) and conducted sensitivity analyses to ensure that including these participants did not unduly influence results [see
online supplement].
Statistical Modeling
Machine learning.
Machine learning methods identify patterns of information in data that are useful in predicting outcomes at the single-participant level (
26,
29,
30). We used a tree-based machine learning algorithm (extreme gradient boosting, or XGBoost) that is fast and has free open-source implementations (
https://github.com/dmlc/xgboost). This algorithm works by fitting an ensemble of small decision trees and iteratively focusing each new tree on predicting misclassified observations from previous trees (
31,
32). The algorithm also includes a number of explicit procedures to avoid “overfitting”—that is, when the algorithm attempts to fit the noise instead of the underlying systematic relationship. Algorithm hyperparameters were selected by cross-validation. Statistical significance was examined by using label permutation testing (
33). Particular care was taken to address issues of imbalanced class proportions when predicting the response variables, including a bootstrapped up-sampling process and adjusted probability thresholds. In addition, given these class imbalances, we focused on a metric known as balanced accuracy [(sensitivity+specificity)/2] whose null distribution is centered on 50%, unlike traditional accuracy (
34,
35) [see
online supplement].
Individual participant variable importance.
Machine learning has been characterized as a “black box” approach with limited interpretability because the rationale behind individual predictions is obscured by the complexity of the model. Researchers typically examine variable importance across the whole sample to determine how much each predictor variable contributes to the overall model. Although this gives some insight into the most influential variables across all predictions, there is no guarantee that they are also the most influential for a specific prediction for a particular individual. With this in mind, we developed and introduced an open-source software library for deriving individual participant-level measures of variable importance from xgboost ensembles (
https://github.com/AppliedDataSciencePartners/xgboostExplainer). We broke down the (directional) impact of each predictor variable for a single participant and illustrated these impacts to show a clinician exactly how the model weighted each variable when making the prediction for that individual. Critically, this means that these “impacts” are not static coefficients as in a logistic regression—the impact of a feature is dependent on the specific path that the observation took through the ensemble of trees [see
online supplement].
Training and testing.
We developed the case-finding model with data from 2008 to 2013. Models were constructed and examined with repeated fivefold cross-validation (three repeats). Relevant descriptions of model discrimination were determined at each stage, including positive predictive values (that is, the probability that a participant did not get treatment, given that the model predicted that the participant would not) and the area under the receiver operating characteristic curve (AUC). To avoid opportune data splits, model performance metrics were averaged across the test folds and repeats.
Independent validation.
Models that show significant performance in test folds during cross-validation may still not generalize to an independent sample (
29,
30,
36). Therefore, we applied our case-finding models to the 2014 cohort that was not used in model development. Participant characteristics were similarly distributed across training and testing data sets, although smoking was noticeably less common and anxiety disorders were more common in 2014.
Analyses were conducted with the R statistical language (version 3.2.2;
http://cran.r-project.org/), and code is available upon request.
Results
Getting Treatment Among Those With a Perceived Need
We focused on adults who stated that they were diagnosed as having depression by a clinician in the past year (N=20,785). The gender and racial-ethnic breakdown of the cohort was as follows: female, 72%; male, 28%; white, 77%; Hispanic, 10%; black, 7%; multiracial, 4%; Asian, 1%; Native American, 1%; and Native Hawaiian/Pacific Islander, 1%. The cohort was mostly between the ages of 18 and 49, and approximately half (54%) had private health insurance. At the time of responding, 54.7% of the sample endorsed five of the nine
DSM criteria for a current major depressive episode. Overall, 30.2% endorsed needing treatment but not receiving it, consistent with recent global estimates that used formal criteria for 12-month major depression (
11).
We developed a case-finding model to identify patients with depression who did not receive mental health treatment among those with a perceived need. In the training cohort (2008–2013), 30.6% of patients needed but did not get treatment. During cross-validation, the model performed significantly above chance in predicting that a participant would not receive needed treatment: balanced accuracy=70.6%±.9%, p<.001; AUC=.79, 95% confidence interval [CI]=.78–.80), with a positive predictive value (PPV) of 50.1%±1.1% and a sensitivity of 73.4%±1.6% (
Table 1). To understand which variables were most influential at a group level, we included a variable importance plot (
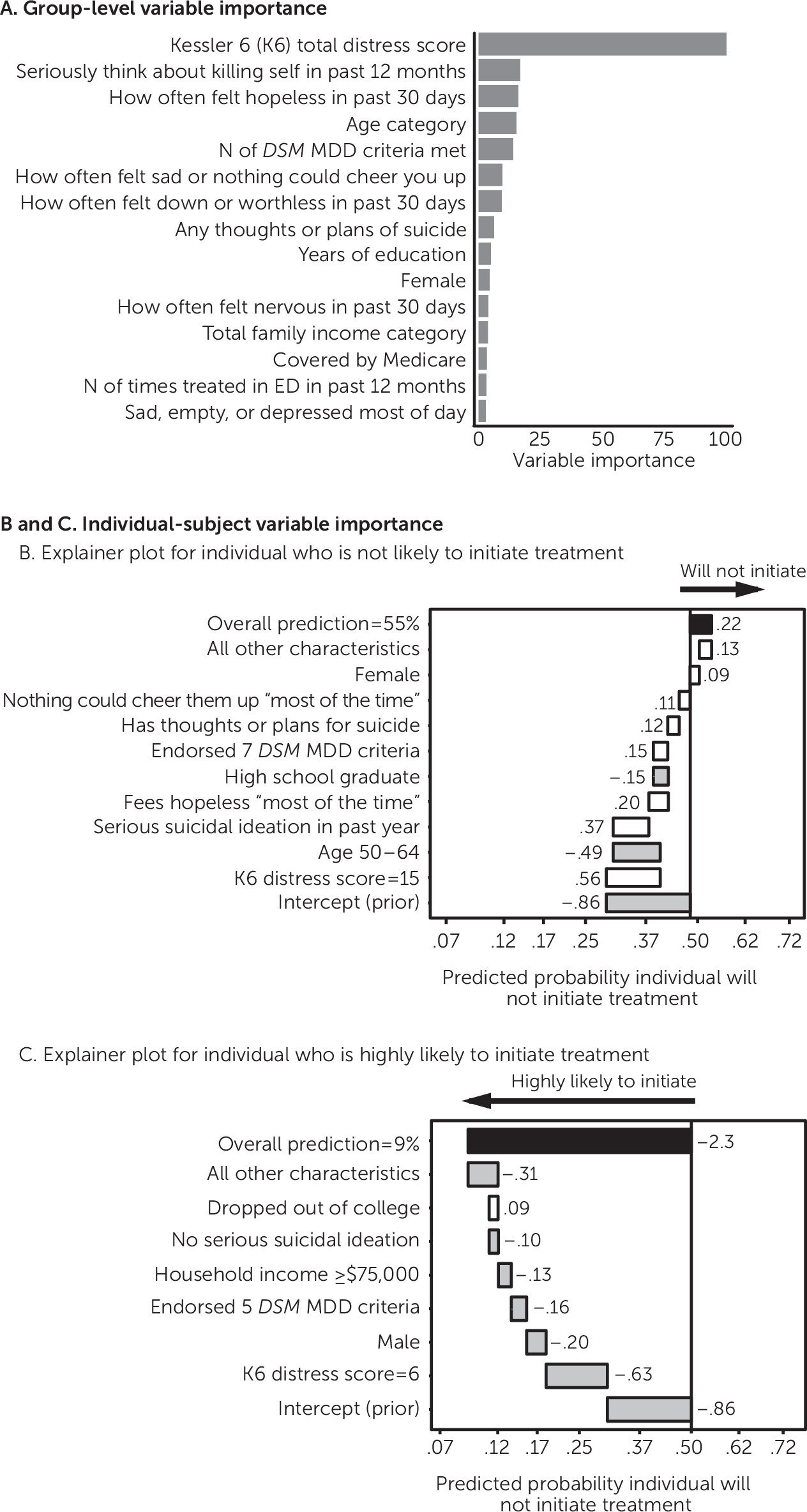
Figure 1A) illustrating the average improvement in accuracy (gain) brought by a particular variable. To show how these predictions can be interpreted for an individual participant, we also derived and illustrated the change in log-odds attributable to each variable for an individual.
Figure 1B shows an explainer plot for an individual predicted not to get needed treatment, and
Figure 1C shows such a plot for an individual with a high predicted probability of treatment initiation.
The case-finding model reliably identified individuals who needed but did not get treatment in the independent 2014 cohort, in which 28.2% of patients did not get treatment (
Table 1). Model performance was again significantly above chance (balanced accuracy, 70.5%, permutation-based p<.01; AUC=.78, CI=.76–.79), with a PPV of 47.5% (CI=46%–49%) and a sensitivity of 72.4% (CI=71%–74%). Therefore, in an independent sample, this model identified over 70% of those who did not initiate treatment, and when the model predicted that a patient would initiate treatment, there was an 86% chance that the participant would do so (negative predictive value of 86.4%). Conclusions remained the same, and performance was comparable when analyses excluded participants for missing data, rather than imputing missing data, and in analyses with more restrictive inclusion criteria. Models that included sociodemographic information alone had much worse performance [see
online supplement.]
Reasons for Not Getting Needed Treatment
Most individuals (2008–2014) endorsed one (53.8%), two (18.2%), or three (12.3%) reasons for not getting treatment (median=1, mean=2.10). The most common reason was being unable to afford the cost (47.7%), and the least common reason was lack of transport or treatment too far (5.8%) (
Table 2). For each reason, we trained a classifier to predict whether patients who did not get treatment would (or would not) endorse that particular reason for not getting treatment. Ten of the 15 self-reported reasons were predictable with a balanced accuracy (range 53%–65%) and sensitivity (range 15%–63%) both above chance (all p<.05) (
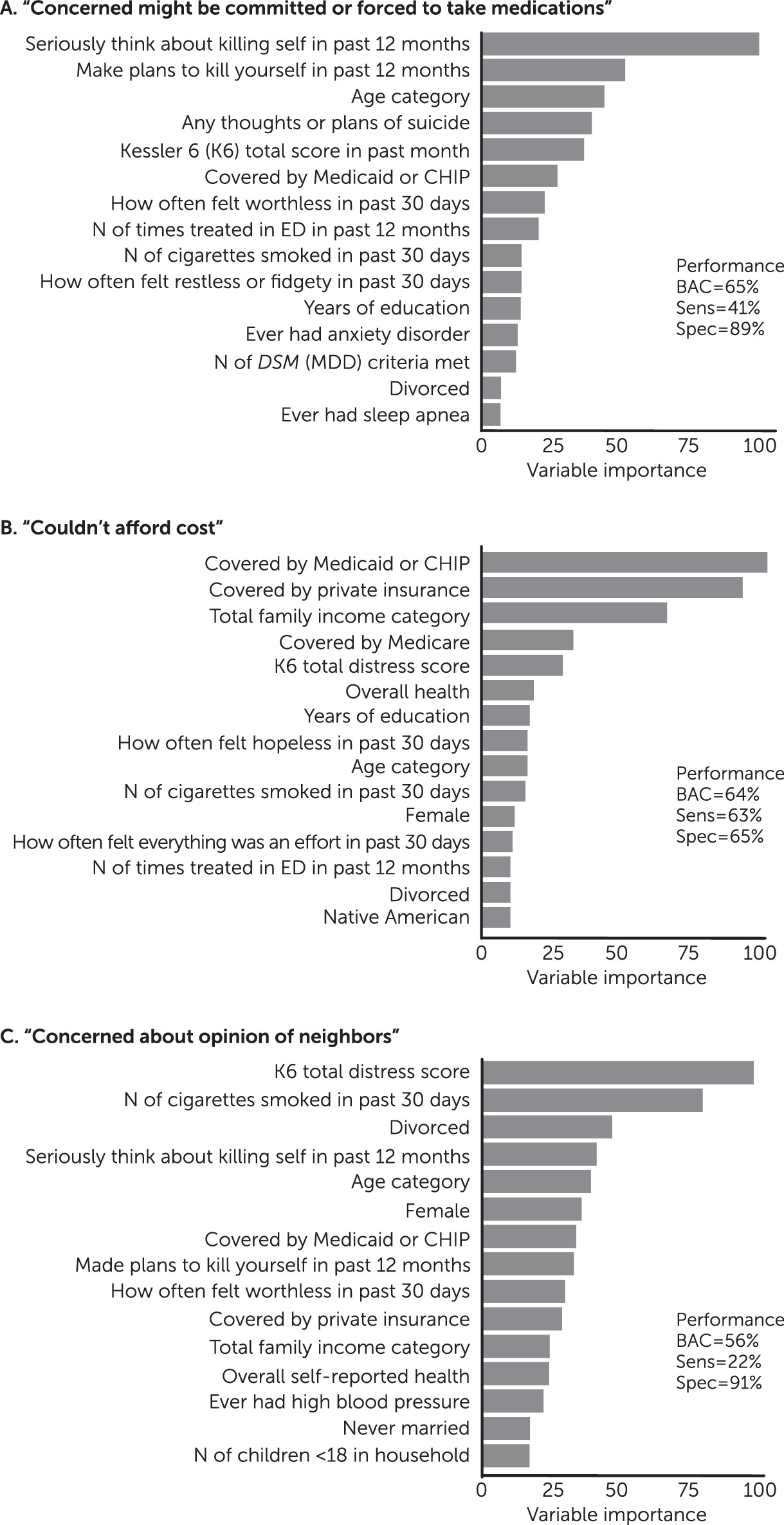
Table 2). For the models with the three highest balanced accuracies, we examined variable importance plots to understand which were most influential at a group level (
Figure 2). For “concerned you might be committed or forced to take medications,” the model relied on suicide-related features. For “couldn’t afford cost,” the model relied on information about health insurance and household income [see
online supplement].
Discussion and Conclusions
These data indicated that between 2008 and 2014, approximately 30% of U.S. individuals with 12-month major depressive disorder reported needing but not receiving mental health treatment. We used a small number of patient-reportable items to develop a case-finding algorithm to identify individuals who did not initiate treatment after receiving a diagnosis and acknowledging treatment need. The balanced accuracy, sensitivity, and PPV of the model were significantly better than chance, even in a large independent validation cohort. Patients who said that they needed but did not get treatment also selected among 15 possible reasons why they did not get treatment. We were able to predict above chance whether patients would endorse a specific reason for 10 of the 15 possible reasons. This combination of large data sets and machine learning tools provides an empirical platform for experimental research and highlights the potential for improving overall treatment outcomes by minimizing the number of people who do not initiate treatment after endorsing a need.
U.S. Preventive Services Task Force 2016 guidelines noted that “research is needed to assess barriers to establishing adequate systems of care and how these barriers can be addressed” (
2). Corroborating recent WHO findings (
11), our data suggest that around 30% of patients with a diagnosis of depression who acknowledged treatment need did not receive it. This study makes an important step toward a broader discussion of reasons for not getting treatment and how to improve treatment initiation (
9,
18,
37,
38). We found that cost or cost-related reasons were perceived as a barrier by more than half the patients, even though some generic antidepressants cost less than $10 per month (free under Medicare Part D and Medicaid and the Children’s Health Insurance Program). Two other primary reasons were not knowing where to go (16.7%) and fear of being committed or forced to take medications (15.2%). Many of the endorsed reasons may reflect depressive symptoms (for example, pessimistic thoughts that treatment will not help may reflect negative thoughts associated with depression).
It is clear that treatment uptake is (and remains) a substantial barrier that prevents universal screening efforts from reaching their full potential for improving population mental health. The utility of depression treatments depends on the first step—treatment initiation. We developed a case-finding tool that can help identify individuals who do not initiate treatment. The most influential variable pertained to suicidal ideation, which is consistent with previous findings of an association between suicidal ideation and deterrents to treatment (
39). Other variables were related to insurance status, demographic factors, and general medical comorbidities, and such variables are not currently used for predictive purposes (
9,
18,
39–
45). An ultimate goal would be to identify individuals who do not initiate treatment (for more concerted outreach) and to estimate how likely they are to accept various treatment options. Levels of risk can then be relayed to the clinician or case manager to help foster shared decision making and minimize barriers to initiating treatment from the outset.
The natural next step is to explore prospectively whether statistical models such as this could help develop and tailor engagement interventions, such as motivational interviewing, psychoeducation, or care management (
16,
46–
48). For example, if an individual is predicted to be concerned about cost, is it effective to subsidize care or highlight cheaper options? Although the NSDUH survey was not designed explicitly for this, it offered an opportunity to develop hypotheses and tools for study to determine whether the approach can improve treatment uptake. Because low motivation, hypersomnia, and low energy are cardinal symptoms of depression, aggressive outreach may be required to encourage some individuals to begin and remain in care (
46,
49), and thus better targeting of patients in need of encouragement may make outreach cost-effective.
The study had some limitations. It relied on self-reported survey data rather than data from clinical practice. Although we focused on adults with diagnoses of depression in the past 12 months, it could not be guaranteed that patients were specifically responding about experiences of depression (versus another mental health issue), and patients may also have had multiple episodes of mental illness in that period. We included persons who had been told by a clinician that they had depression, which may have biased the sample toward those with more easily recognizable symptoms or with better access to providers. In addition, at least some patients with major depression experience sudden gains and may have recovered without treatment (
14,
50), although long-term outcomes are generally not favorable for untreated patients (
18).
Although prediction of specific concerns for not getting treatment was statistically robust, the predictions may best be considered as a helpful warning sign rather than requiring urgent action. An advantage of these models is that they require only simple data that can be obtained quickly. However, they may be improved by inclusion of more training data or by integration of other sources of predictor variables (for example, electronic medical records and feedback from caregivers and family members); this would help improve the model’s sensitivity. Nonetheless, the model’s performance is comparable to that of other predictive models in psychiatry that included large validation samples (
30,
36,
51). Unfortunately, the data did not permit patients to indicate a lack of treatment availability (or unacceptable wait time), and thus we focused on patient-perceived barriers rather than structural system-level barriers. Causal associations cannot be drawn from this retrospective, cross-sectional analysis, especially because NSDUH does not sequence symptoms, perceived need, and the decision not to obtain treatment. Finally, it is not clear to what extent the context of health and mental health care in the United States influenced both the predictor variables (for example, public insurance), the reasons (for example, cost), and the outcomes, and thus it will be important to examine similar data in countries with universal or other health care models.
Acknowledgments
The authors thank Gregory McCarthy, Ph.D., Myrna Weissman, Ph.D., and Harlan Krumholz, M.D., for advice and thoughtful comments on the manuscript.