For more than 10 years, and more specifically over the past 4 years, the American Psychiatric Association (APA) has been revising the diagnostic criteria in the
Diagnostic and Statistical Manual of Mental Disorders (DSM). The DSM-5 revision process has aimed to use evidence from clinical practice and existing epidemiological, neurobiological, clinical, and genetics literature to develop revised or new diagnostic criteria that better capture the various mental disorders to help clinicians provide more accurate diagnoses. Effective detection and treatment of mental illnesses depend strongly on the accuracy of the conceptualization and operationalization of the diagnostic criteria used in their assessments. However, evidence from the literature indicates that the current diagnostic criteria for a number of mental disorders are unclear and do not adequately capture their complexities, thereby compromising diagnosis and treatment potential (
1–
5). In particular, persons whose symptom presentations are mixed may exhibit pronounced declines in functioning and quality of life (
1–
5), but the current categorical structure of DSM diagnoses does not facilitate the assessment of symptoms across disorders. As part of the DSM revision process, the integration of cross-cutting dimensional measures has been proposed. This is seen as a way of addressing the realities of comorbid symptom presentations, allowing clinicians to better assess variations within diagnoses (e.g., accounting for mood and manic symptoms within schizophrenia) and symptoms across diagnoses, and providing longitudinal tracking of patients' symptoms over time (
6).
The face and construct validity of the revised DSM-5 diagnoses were subjectively confirmed by the work groups that proposed the diagnostic changes. The diagnostic changes were supported by evidence from literature reviews and secondary data analyses conducted by the work groups. Additional reviews by the general public and by mental health professionals of varied clinical disciplines were done when the criteria were released for public commentary on the DSM-5 web site (
www.dsm5.org).
The DSM-5 Field Trials were proposed to objectively evaluate the clinical utility and feasibility and to estimate the reliability and, where possible, validity of the proposed diagnoses and dimensional measures in the environments in which they will be used (
7). This entailed testing in clinical populations across multiple sites and using clinicians of various mental health disciplines. The use of multiple sites was necessary to capture the diversity of clinicians who will use the manual in clinical assessments, the diversity of patients who will seek assessments and treatments for their mental illnesses, and the diversity of clinical settings that will require the use of DSM-5. The results of the field trials were intended to inform the DSM-5 decision-making process, but in and of themselves would not determine inclusion or exclusion of diagnoses in the final version of DSM-5.
The most difficult issue to address was the estimation of the reliability coefficients of the categorical diagnoses (i.e., intraclass kappas). The goal was to estimate intraclass kappas with standard errors less than 0.1 for the diagnoses evaluated (
7,
8). The design of the field trials was therefore driven primarily by the need to estimate these intraclass kappa coefficients well, which in turn meant that the reliability coefficients of the dimensional measures (i.e., intraclass correlation coefficients [9]) would be well estimated, given the need for smaller sample sizes for those goals. These sample sizes were also sufficient to allow for the examination of clinician assessments of the clinical utility and feasibility of the proposed changes to DSM-5. The aim of this article is to describe and discuss the design, sampling strategy, implementation, and data analytic processes of these field trials.
Method
Study Design, Sample Size, Sampling Strategy
The DSM-5 Field Trials were conducted over a 7- to 10-month time period in six adult and four pediatric sites in the United States and one adult site in Canada using centrally designed protocols (
Table 1). The centrally designed protocols, associated measures, study information sheets, and consent or assent forms were approved by the institutional review boards at the American Psychiatric Institute for Research and Education and the 11 field trial sites. All participating clinicians, principal investigators, and research coordinators completed human subjects training before participating.
The main interest was to determine the degree to which two clinicians would agree on the same diagnosis for patients representative of the DSM clinical population; therefore a design was chosen that was comparable to that used for the DSM-III Field Trials in that the DSM-5 Field Trials were designed, conducted, and analyzed centrally to avoid any biases associated with the work groups evaluating their own work. In contrast to the DSM-III and DSM-IV Field Trials, which were split between interobserver and test-retest reliabilities, the DSM-5 Field Trials focused entirely on the test-retest design. This required that a representative sample of patients from the relevant population be independently evaluated twice using DSM-5 criteria for the diagnoses being tested, ensuring independence of errors—crucial to the estimation of reliability coefficients (
8). Specifically, two independent evaluations of each patient were required, with a short (4 hours to 2 weeks) interval between the evaluations. This interval was determined to be long enough to warrant the assumption of independence of the diagnoses at the two study visits but short enough to ensure the occurrence of very few new-onset diagnoses or spontaneous recoveries.
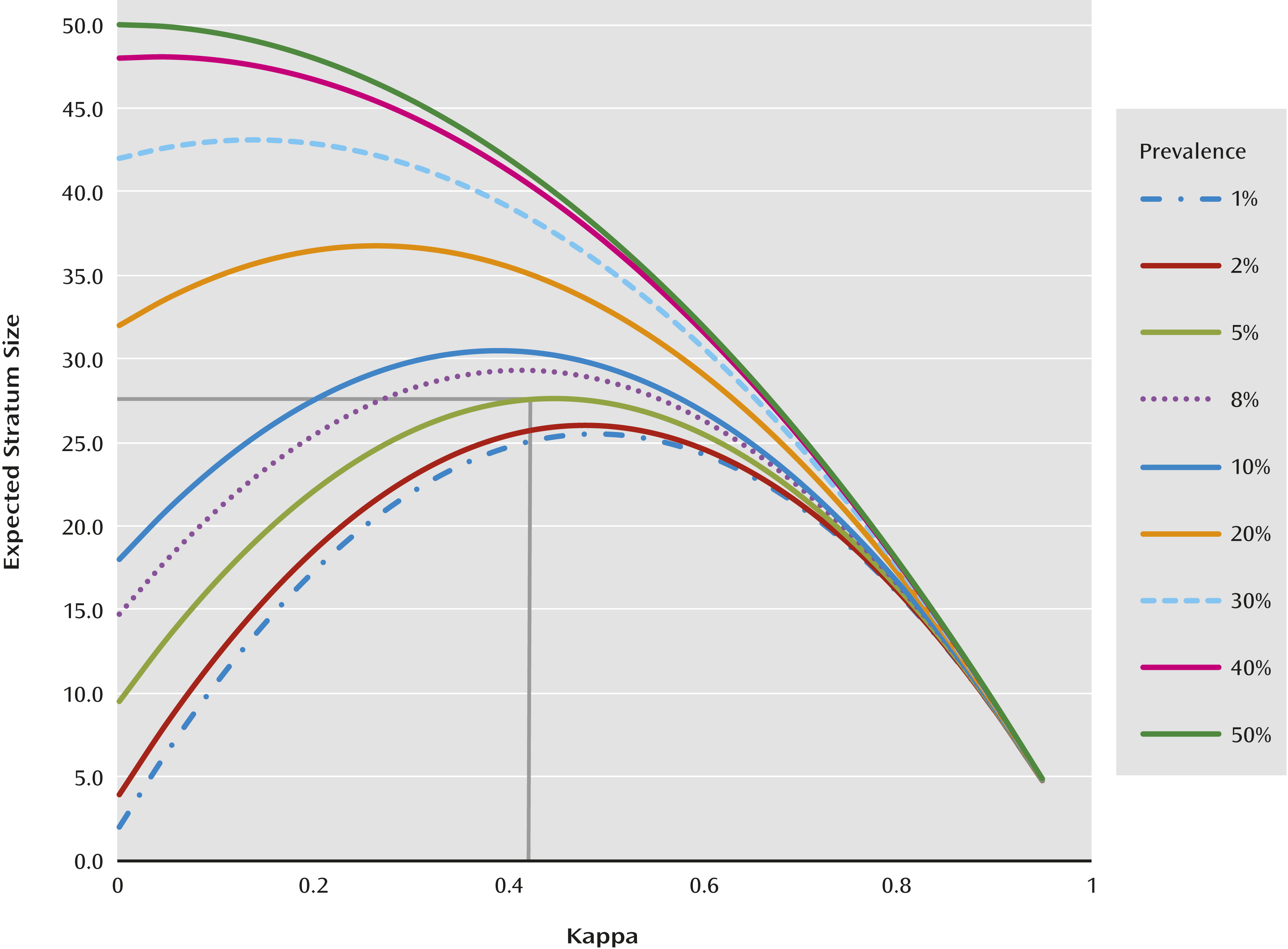
If a simple random sample is used, with prevalences as low as those of many of the diagnoses being evaluated in the DSM-5 Field Trials, the sample size per diagnosis, per site, that is necessary to obtain a standard error less than 0.1 is very large (
Figure 1). For example, for a rare diagnosis with a prevalence of 0.05, estimating kappa with a standard error of less than 0.1 requires 28 cases of individuals with the diagnosis, which would require a sample size of 560 patients (
Figure 1). This is much larger than was feasible at individual sites in a limited period of time. Furthermore, there are often site differences in reliabilities, depending on the nature of the clinical population samples, clinician experience, and so on (
10). As such, an adequate sample size per diagnosis had to be planned at each site so that the reliability of the diagnoses could be estimated, which would then enable comparison of reliabilities across sites and pooling the estimates where appropriate.
To increase the precision of estimation, a stratified random sampling approach was used. This enabled the estimation of kappa with a standard error of less than 0.1 using smaller total sample sizes (
Figure 1). Each of the 11 field trial sites was to field test two to five target diagnoses, but some sites, when asked by the APA, chose to test four to seven target DSM-5 diagnoses. The classification into strata was based on the patient’s DSM-IV diagnoses corresponding to each of the target DSM-5 diagnoses at the site. For diagnoses that were new to DSM, screening questions on existing symptoms that had a high probability of indicating the new diagnoses were used to stratify patients (
Table 2). Consecutive patients at each site were classified into four to seven different strata, one corresponding to each target diagnosis. Patients having DSM-IV diagnoses other than those targeted at the site were classified into a stratum labeled “other diagnosis.” Therefore, five to eight strata were assembled at each site.
Because of comorbidity, patients were often eligible for two or more strata, in which case they were assigned for sampling to the stratum that was rarest at that site. In instances where a patient had comorbid conditions that were equal in prevalences, he/she was randomly assigned to either of the strata. Within each stratum, patients were then sampled for testing. This was done to oversample for the target diagnoses and to increase the chance that representative samples of relatively rare categorical diagnoses would be obtained. With the stratified sampling approach, it was found that sampling 50 subjects per stratum would likely result in a standard error less than 0.1 regardless of the prevalence (yet unknown) or the true population kappa (yet unknown). Fifty subjects per stratum was a fail-safe sample size that would work well for all values regardless of the true prevalence and population kappa (
Figure 1). However, smaller sample sizes could suffice in some cases, but a lower limit of seven was set.
Site Selection and Description
The seven adult and four pediatric sites were selected from a pool of 49 institutions that submitted applications in response to the Request for Applications posted by the APA in April 2010. Criteria for site selection included overall quality of the application; past experience conducting large clinical studies; and site characteristics that included patient volume, clinician staffing (i.e., minimum of eight participating clinicians at a site), prevalence and type of mental disorders typically seen at the site, and an adequate research infrastructure to accommodate the complexities of the study design.
Eight or more volunteer clinicians of varied psychiatric/mental health disciplines, levels of training (a minimum of 2 years of postgraduate psychiatric training [i.e., PGY-2 or greater]), and years in practice were recruited. All clinicians within a study site were eligible to participate provided they had current human subjects training and were willing to participate in the DSM-5 Field Trial clinician training sessions. The level of training provided was comparable to what would be available to any clinician after publication of DSM-5 and involved orientation to changes in diagnostic criteria across the DSM, particularly new diagnoses or those with major changes. Participating physicians were provided continuing medical education credits, and all other clinicians were provided certificates of participation that could be used toward obtaining continuing education units from the licensing body for their disciplines. All participating clinicians received remuneration for each patient assessed ($100 per adult patient interview, $150 per child/adolescent patient interview) and were informed that their participation would be acknowledged in DSM-5.
Patient Recruitment Process and Sampling Frame
Patient Recruitment Screening Forms (PRSFs) were completed by intake or treating clinicians on all consecutive patients seen at the site for routine clinic visits during the study period. The PRSF inquired about the patient’s age, sex, date of clinic visit, clinic status (i.e., new versus existing patient at the site), length of time in the care of the treating clinician (for existing patients), and whether the patient was currently symptomatic for any DSM-IV diagnoses or had high-probability symptoms associated with the DSM-5 proposed diagnoses being tested at the site (
Table 2). “Currently symptomatic” was defined as having enough symptoms to meet criteria for the diagnoses at the time the PRSF was being completed.
In order to maintain blindness to the patient’s stratum assignment, clinicians who completed the PRSF were not eligible to complete diagnostic interviews for the patients they screened. Completion of the PRSF on consecutive patients was necessary to obtain the information needed to define the totality of patients seen in the clinic (i.e., the sampling frame) and to obtain the prevalence estimates for each DSM-IV diagnosis that defined a stratum associated with the DSM-5 diagnosis targeted at the site. This information was later used in the calculation of sampling weights.
Eligibility Criteria, Stratum Assignments, DSM-IV Prevalence Estimates, and Sampling Weights
All interested patients, identified on the PRSF, were referred to the research coordinator to determine eligibility and stratum assignment. Eligible patients were those who were currently symptomatic for any DSM-IV diagnoses or high-probability symptoms associated with the DSM-5 diagnoses being tested at the site (i.e., target diagnosis) irrespective of the number of diagnoses and the type and status of treatment. Adult patients without cognitive impairment or other impaired capacity were also required to be able to read and communicate in English. Patients with cognitive impairment or other impaired capacity had to have a caregiver who could read and communicate in English. In the pediatric version of the field trials, patients had to be at least 6 years old and were required to have a parent or guardian who could read and communicate in English, would accompany the patient to the study appointments, and would complete the parent/guardian version of the study measures. At the Colorado site, the lower age limit was 5 years, given the testing of the diagnostic criteria for PTSD in children and adolescents.
Patients who were currently symptomatic with one or more of the target diagnoses being tested at a site were eligible for potential assignment to one of the target diagnosis strata. Patients who were currently symptomatic for any other DSM-IV diagnoses (not including the target diagnoses) were eligible for potential assignment to the “other diagnosis” stratum.
Each enrolled patient was assigned to two randomly selected participating clinicians, who were new to the patient and blinded to the patient’s stratum membership for the test (visit 1) and retest (visit 2) diagnostic assessments. Clinicians were blinded to each other’s ratings. Each adult patient was offered a remuneration of $40 per study visit. The participating parent or guardian of each pediatric patient was also offered remuneration ($40 per study visit) as was the participating child/adolescent (a $25 gift card).
The estimated DSM-IV prevalence of a diagnosis in each clinic population was the proportion of all “currently symptomatic” patients with that diagnosis as indicated by the patient’s intake or treating clinician. Individuals with more than one of the diagnoses being field tested at a site qualified for more than one DSM-IV stratum and contributed to the prevalence estimate for each condition.
For purposes of sampling weights, each patient who qualified for more than one stratum was assigned to the rarest stratum at that site. The sampling weight for each target diagnosis stratum was the proportion of those in the sampling frame assigned for sampling to that stratum. Patients with comorbid conditions contributed only to the sampling weight for the stratum to which they were assigned. The number of patients included in the sampling frame, the DSM-IV prevalence of the targeted diagnoses, and sampling weights for each site are outlined in
Table 3.
Assessment Method and Familiarization
An important decision in the planning process was to have central protocol development, implementation, data collection, as well as ongoing monitoring of the DSM-5 Field Trials, all of which required the use of an electronic data capture system. The National Institutes of Health-funded Research Electronic Data Capture (REDCap) system at Vanderbilt University (
11) was modified to meet the needs of the DSM-5 Field Trials. The DSM-5 Field Trial REDCap system included a patient component with all patient-rated measures, programmed for easy access by multiple simultaneous users, and scoring of measures with real-time transmission of results. The clinician component included all clinician-rated dimensional measures and diagnostic checklists and was accessible by multiple clinicians at the same time across different time zones. A research coordinator component enabled careful coordination and monitoring of the workflow within sites while enabling central monitoring of the workflow across sites by the DSM-5 Field Trial Project Manager. Patients could only access their own information, and clinicians could only access information on patients assigned to them. The functionality and ease of use of the patient and clinician components of the DSM-5 REDCap system were pilot tested and the systems modified accordingly before implementation in the DSM-5 Field Trials.
Familiarization: clinician training.
Clinician training occurred in two parts. Part 1 involved a 1-hour web-based training session introducing the batteries of patient- and clinician-rated DSM-5 cross-cutting dimensional measures, including information on their development and function and how the results should be interpreted and potentially used as diagnostic interviews. Clinicians also had a brief orientation to some of the changes in DSM-5, such as new diagnoses and those with major reconceptualization. The training also included orientation to the DSM-5 Field Trial's REDCap system, including how to log on and access the various DSM-5 diagnostic checklists, clinician-rated dimensional measures, and the results of the patient-rated measures. Clinicians were given unique usernames, passwords, and access to a practice version of the system and encouraged to practice with the system prior to part 2 of the training session. They were also encouraged to familiarize themselves with the proposed changes to the diagnostic criteria across DSM.
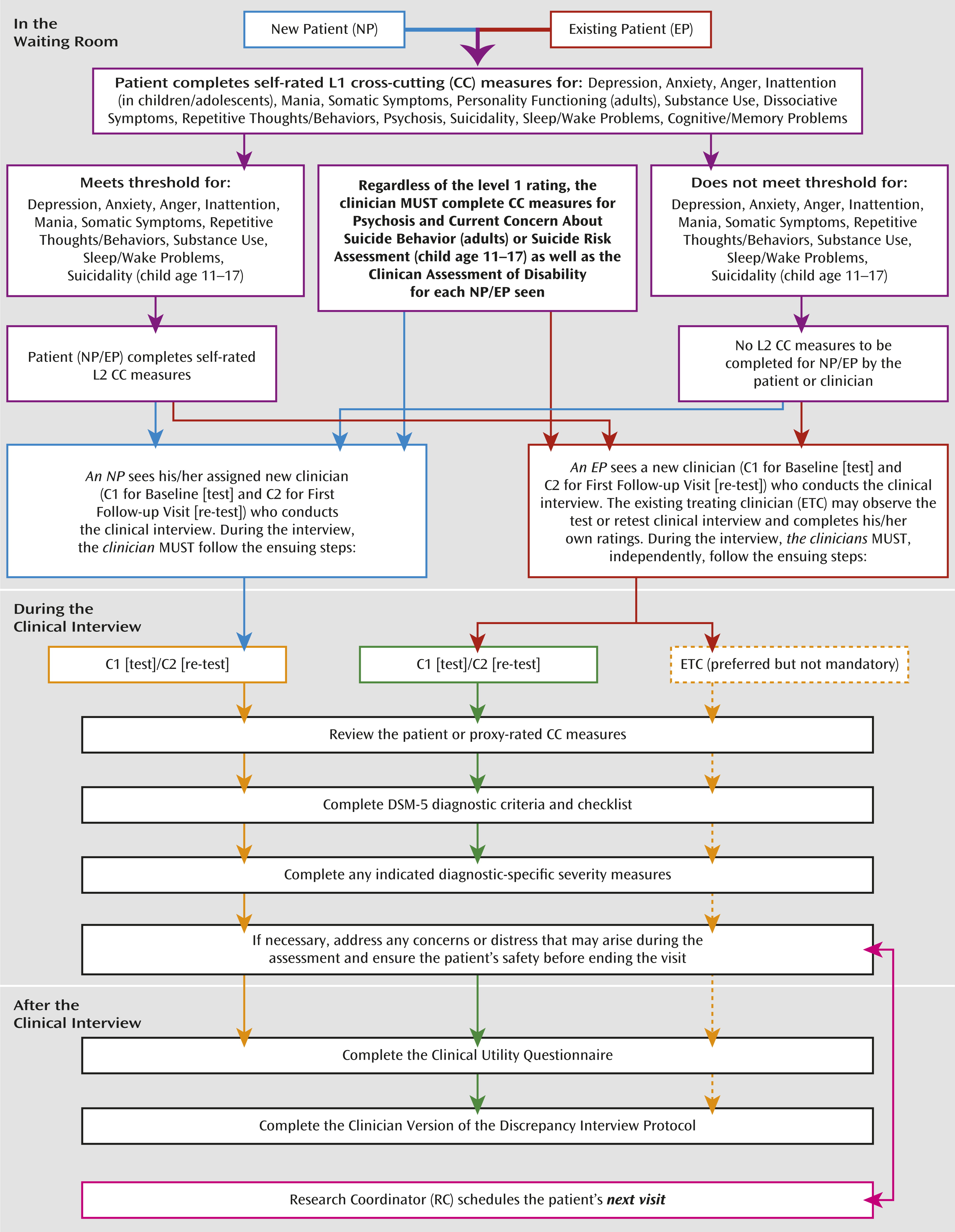
Part 2 of the clinician training was an in-person, 3-hour session conducted by the DSM-5 Research Team at APA (D.E.C., W.E.N., D.A.R.). Clinicians were provided with a training manual that outlined the study protocol and study visit workflow (
Figure 2), the DSM-5 diagnostic checklists, and clinician- and patient-rated measures. The session included more detailed information on DSM-5 criteria and the DSM-5 dimensional measures being incorporated into the diagnostic schema. A mock clinical interview was conducted to demonstrate the diagnostic interview process and how to incorporate the clinician component of the DSM-5 Field Trials REDCap system. Ongoing interactive Web-based training sessions were provided on an as-needed basis or as new clinicians joined the study.
Familiarization: research coordinator training.
Given the multisite nature of the DSM-5 Field Trials, it was important to have centralized training of the research coordinators across field trial sites. Each site’s lead research coordinator or primary back-up attended a full-day in-person training session conducted by the DSM-5 Research Team at the APA (D.E.C., W.E.N., D.A.R., L.G.). The goal of the session was to familiarize the lead research coordinators with the study protocol (
Figure 2), including their roles and responsibilities throughout the study. All research coordinators had to attend a 2-hour interactive web-based session during which they were oriented to the functionality of the research coordinator component of the DSM-5 REDCap system and its connectedness to the patient and clinician components of the system. Ongoing interactive web-based training was available to the sites as needed or as new research coordinators joined the study. Biweekly meetings were held throughout the course of the field trials to immediately address any concerns. Real-time troubleshooting assistance was provided by the APA research team.
Data Analysis Plan
All analyses were based on the sampling weights associated with the strata at each site and conducted by using SAS statistical software and SUDAAN, where necessary. Descriptive statistics (mean, standard deviation, quartiles, correlation coefficients, and frequency distributions) were estimated for the study population at each site (i.e., patients and clinicians) and for each dimensional measure.
Reliability of the categorical diagnoses/variables.
Test-retest reliability for the categorical (binary) diagnoses was based on the intraclass kappa (estimated for a stratified sample) and presented with a two-tailed 95% confidence interval (CI) using bootstrap methods (
12,
13). Intraclass kappa is the difference between the probabilities of getting a second positive diagnosis between those with a first positive and those with a first negative diagnosis (
14), thus reflecting the predictive value of a first test to a second. Given the stratified sampling approach for the study, sampling weights for each site were used to obtain unbiased site-specific estimates of intraclass kappa for each categorical diagnosis tested. Equations 1 and 2 below were used to calculate intraclass kappa coefficients for a stratified sample, for each diagnosis tested.
Where:
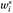
= the sample weight = proportion assigned for sampling in a particular stratum. If a patient was eligible for two or more strata, he/she was assigned to the rarest stratum.
Qi2 = proportion of those in stratum i where both clinicians diagnosed the particular diagnosis X.
Qi1 = proportion of those in stratum i where only one of the two clinicians diagnosed the particular diagnosis X.
Qi0 = proportion of those in stratum i where both clinicians did NOT diagnose the particular diagnosis X.
Note: Qi2 + Qi1 + Qi0 = 1
Px = the overall prevalence of the target diagnosis in the population.
To obtain the 95% CIs on the kappa, a bootstrap method was utilized (
12). The simple meta-analytic approach, which involved the weighted average of the reliability coefficients, was used to calculate pooled intraclass kappa estimates and their 95% CIs for diagnoses tested at two or more sites. In instances where the 95% CIs for intraclass kappas for the same diagnosis did not overlap for all sites at which it was tested, a cautionary note was associated with the pooled estimate. The results of the test-retest reliability of the DSM-5 categorical diagnoses tested in these field trials are presented in an accompanying article by Regier and colleagues (
15).
The following standards were set for the reliability coefficients for DSM-5 categorical diagnoses: intraclass kappas of 0.8 and above were “excellent”; from 0.60 to 0.79 were “very good”; from 0.40 to 0.59 were “good”; from 0.20 to 0.39 were “questionable”; and values below 0.20 were “unacceptable” (
8). The goal of the DSM-5 Field Trials was to attain intraclass kappas at least in the “good” reliability range (
8).
Reliability of the dimensional measures.
Test-retest reliability estimates for dimensional measures (continuous and ordinal) were estimated using parametric intraclass correlation coefficients (ICCs) and presented with their two-tailed 95% confidence intervals, using sampling weights and bootstrap methods. The parametric ICC is a measurement of agreement or consensus between two or more raters on the same set of subjects where the measures are assumed to be ordinal or continuous and to be normally distributed (
9). The ICC is a “relative measure of reliability” in that it reflects a ratio of the variability between subjects to the total variability in the population sampled (
16,
17). The parametric ICC was used because of its reported robustness (
9) and because it reflects the predictive value of a first measure to a second.
Two ICC models were used in this study: Type- (1, 1), a one-way random model of absolute agreement and Type- (2, 1), a two-way random model of absolute agreement. A one-way random model of absolute agreement was used when determining the reliability estimates for each clinician-rated dimensional measure given that each patient was rated by a different and randomly selected clinician from a pool of participating clinicians within each site (
9). The two-way random model of absolute agreement was used when determining the reliability estimate for each patient-rated dimensional measure since each patient was rated by the same raters (i.e., self or proxy [9]). Site-specific reliability coefficients were calculated for each dimensional measure. Pooled estimates, based on a meta-analytic approach, were also calculated since the same measures were used across sites. In instances where the 95% CI for the ICC estimates for the same dimensional measure did not overlap for all sites, a cautionary note was associated with the pooled estimate.
The robustness of the parametric ICC was checked by using a nonparametric ICC for comparison. In the nonparametric approach, patient scores on each dimensional measure were ranked and the one-way and two-way random ICC models of absolute agreement were used to estimate the reliability coefficient. In general, the parametric ICC method was more conservative and therefore reported for the field trials of the DSM-5 cross-cutting dimensional measures in the accompanying paper by Narrow et al. (
6).
The standards proposed for the DSM-5 dimensional measures were as follows: ICCs over 0.80 were “very good”; from 0.60 to 0.79 were “good”; from 0.40 to 0.59 were “questionable”; and values below 0.40 were “unacceptable” (
8). These standards correspond to those for IQ testing, for example (
16,
17). These standards, like any standards, are suggestions. In this case, they are based on existing reliability estimates of psychometric tests that yield dimensional outcomes (
16–
19).
Convergent validity.
To examine convergent validity, receiver operating characteristic (ROC) curves (
20,
21) were used. ROC curves were used to examine the association between the clinician- and patient-rated dimensional measures and their associated categorical diagnoses. To maintain the assumption of independence of the ratings, clinician-rated dimensional measures of one clinician were compared with the categorical ratings by the second, independent, and “blinded” clinician. Similarly, since clinicians were privy to the patient-rated results simultaneous to completion of the categorical diagnoses, patient-rated dimensional measures at visit 1 were compared with the categorical diagnoses at visit 2 and vice versa. These results will be presented in an upcoming article.
Results
Overall, 7,789 patients were seen across the 11 field trial sites and screened during the study period (5,128 in adult sites combined and 2,661 in pediatric sites combined [
Table 3]). Of these, 4,110 were interested, eligible, and assigned for sampling (N=2,791 and 1,319 across the adult and pediatric sites, respectively). Written informed consent was obtained for 1,755 of 2,791 adult patients and 689 of 1,319 child/adolescent patients. The majority of the patients who provided written consent for field trial participation completed visit 1 (N=2,246 of 2,444 patients overall; 78%–98% in the adult field trials and more than 98% in the pediatric field trials). The demographic characteristics of these patients are presented in
Table 4 (for adult sites) and
Table 5 (for pediatric sites). Overall, more than 86% of the patients who completed visit 1 also completed visit 2.
The patient population across adult (
Table 4) and pediatric (
Table 5) field trial sites varied. For instance, compared with the other six adult field trial sites, UT-SA had a larger proportion of Hispanic patients (51.2% relative to less than 15% in the other sites). Indeed, the high proportion of Hispanic/Latino patients was one factor in the site being selected for the field trials. The proportion of patients of black/African-American descent varied from 0.9% at the Mayo site to 40% at the Dallas VA site. Similarly, the proportion of male patients varied from 32.7% at the Penn site to 85% at the Dallas VA site. Among the pediatric sites, the patient populations at Baystate and Columbia/Cornell consisted of greater than 40% Hispanics compared with 15% and 12% at Colorado and Stanford. The proportion of patients of Black/African-American descent was about 10% at Baystate, Colorado, and Columbia compared with <1% at Stanford. At Stanford, a majority of the patients (73.1%) lived in two-parent households compared with 48.5%, 52.4%, and 57.0% at Baystate, Columbia, and Colorado respectively. Differences in the patient population across sites were expected given the variability in the sites selected for the DSM-5 Field Trials (e.g., general psychiatry, Veterans Health Administration, and geriatric psychiatry settings).
Two hundred eighty-six clinicians from various clinical disciplines participated in the DSM-5 Field Trials. Participating clinicians included board-certified psychiatrists and trainees (PGY 2+), licensed clinical and counseling psychologists and neuropsychologists (i.e., doctorate-level training) and those in supervised practice, master's-level counselors, licensed clinical social workers, and advanced practice licensed mental health nurses. Of the 286 clinicians, seven functioned purely as intake or referring clinicians and did not complete any diagnostic interviews. The remaining 279 clinicians completed, on average, seven or more diagnostic interviews. The characteristics of the clinicians who completed the diagnostic interviews in the DSM-5 Field Trials are presented in
Table 6 (for the adult sites) and
Table 7 (for the pediatric sites). Clinicians who participated in diagnostic interviews in the DSM-5 Field Trials varied by clinical discipline, years in practice, and other clinician characteristics. Having the diagnostic changes to the DSM tested by clinicians of varied disciplines and other characteristics was a goal of the DSM-5 Field Trials. The variations in the clinician discipline and experience may, however, limit the ability to compare reliability estimates across field trial sites and should be taken into consideration when considering the results presented in subsequent articles (
6,
15). The results of the quantitative and qualitative analyses of the clinicians’ evaluation of the clinical utility and feasibility of the diagnostic changes to the DSM will be presented in an upcoming article.
As can be seen in both adult and pediatric sites (
Table 3), very few of the diagnostic strata achieved the fail-safe sample size goal of 50 patients. As noted earlier, a lower sample size may be adequate in some cases, but a lower limit of seven was set for the estimation of reliability for the field trials. At a sample size of six or less, the field trial for a target diagnosis at a site was declared “unsuccessful,” in which case intraclass kappa was not estimated and the stratum was folded into the “other diagnosis” group. Of the 60 strata across the 11 field trial sites, 10 were unsuccessful by this definition (four across adult and six across pediatric sites). For example, at the UT-SA site, only six patients completed visits 1 and 2 in the attenuated psychosis syndrome stratum.
The DSM-5 Field Trials aimed to obtain precise estimates of the reliability of the categorical diagnoses and the dimensional measures (i.e., a standard error ≤0.1 as indicated by 95% CI sizes no greater than 0.5 [i.e., used to define a “successful” field trial]) (
3). Of the remaining 50 categorical diagnostic strata with stratum sample size greater than six across the 11 field trial sites, 11 were not “successful” (seven across adult and four across pediatric sites). Some of these 11 field trials had high kappa coefficients, but even so, the wide confidence intervals indicated that the true kappas could not be estimated with precision (see Regier et al. [
15]). Results of field trials declared “unsuccessful” were excluded in any pooled estimate for a DSM-5 diagnosis.
The field trials for dimensional measures that were completely missing for more than 25% of the sample or had missing data for more than 25% of the items were declared unsuccessful and the reliability estimates were not calculated. As with the categorical diagnoses, a field trial for a particular dimensional measure was unsuccessful in estimating the reliability coefficient with precision if the size of the 95% CI was greater than 0.5, even if the reliability coefficient was high (see Narrow et al. [
6]). Results of a field trial for a dimensional measure that was declared unsuccessful were not included in the pooled estimate for that measure.
Discussion
The DSM-5 Field Trials were crucial for testing the feasibility, clinical utility, test-retest reliability, and (where possible) the validity of DSM-5 diagnoses that were new to DSM, represented major changes from their previous versions, or had minor changes but were of significant clinical and public health importance. These field trials were a multisite study that utilized a rigorous test-retest reliability design with stratified sampling, thereby improving upon previous DSM field trials’ sampling methods and generalizability. The DSM-5 Field Trials can be most closely compared with the DSM-III Field Trials in that both attempted to generate representative samples of patients and clinicians. The DSM-5 Field Trials' stratified sampling approach is in contrast to the approximation of simple random sampling used in the DSM-III Field Trials. The sampling used in the DSM-III Field Trials resulted in small sample sizes, below the standards set for the DSM-5 Field Trials, for the low-prevalence diagnoses tested.
Even with the use of the stratified sampling approach, the field trials for some DSM-5 diagnoses were unsuccessful in meeting the standards set for DSM-5 and, as such, trustworthy reliability coefficients could not be obtained. This situation resulted from unrealistic assessments of the patient flow and total staff effort needed to recruit 50 patients per stratum at the field trial sites, particularly for rare disorders. The results of the DSM-5 Field Trials were intended to help to inform the DSM-5 decision-making process (along with many other factors unrelated to field trials), which would not be available for DSM-5 diagnoses with unsuccessful field trials. However, since reliability information from the field trials was only one of many factors to be used in the DSM-5 decision-making process, field trials were not done for every DSM-5 diagnosis, and the few that were not “successful” were added to that list.
The DSM-5 Field Trials were conducted across a variety of clinical settings and hence captured a heterogeneous overall patient population. However, since the sites were primarily large academic clinical settings with research infrastructure that enhanced the feasibility of the implementation of the complex study protocol, the results might not be generalizable to patients seen in solo or small group practices or other community-based settings. Patients who present to academic settings may be different from those in other settings in their symptom presentations. For instance, if patients present to academic/large clinical settings when they have more severe symptoms and to solo or small group practices when they have less severe or subthreshold symptom presentations, reliability of the categorical diagnoses and dimensional measures might be different.
The intended primary purpose of DSM-5 is to support clinical use. Thus, the assessment of DSM-5 diagnoses in adult and pediatric sites in the United States and Canada, with the participation of mental health professionals of varied disciplines, enhances the generalizability of findings. Clinicians of varied clinical disciplines, years in practice, race/ethnicity, and other characteristics completed the diagnostic interviews used in the estimation of the reliability coefficient for the various diagnoses. This is a major strength of the field trials in that the reliabilities of the DSM-5 diagnoses were assessed by the clinicians who would use the manual in clinical care. A weakness, however, is that the clinician population in academic/large clinical settings may differ from those in solo or small group practices or nonacademic settings. Clinicians in solo or small group practice might have less time or resources to complete the diagnostic interview in a fashion similar to that of the study clinicians. We attempted to mitigate this difference by integrating the study’s diagnostic interviews into busy clinical settings and practitioner schedules and enrolling clinicians whose time was not spent solely in research endeavors.
In assessing the reliability estimates for the categorical diagnoses (i.e., intraclass kappas) in comparison to those obtained from the DSM-IV Field Trials, one needs to keep in mind the different methods used in the two field trials. The DSM-IV Field Trials enrolled carefully selected patients likely to have the target disorder, excluded patients with high levels of comorbidity and other confusing presentations, and used diagnosticians highly trained on a specific diagnostic instrument. All of these factors will tend to produce higher kappa estimates compared to the more naturalistic field trial methods employed in the DSM-5 Field Trials, for which patient exclusion criteria were minimal and diagnostic instruments requiring training were not used (
8).
Further publications (
6,
15) detail the outcomes of the DSM-5 Field Trial methodology as applied to specific diagnoses and dimensional assessments. The methodological approaches described herein demonstrate efforts to use an empirically sound approach to assessing diagnostic quality. Since DSM-5 is intended to be a living document, these field trials also were important in providing a stepping stone to conduct future field trials in routine clinical settings.
Acknowledgments
The authors acknowledge the efforts of Paul Harris, Ph.D., and his research team at Vanderbilt University, including Brenda Minor, Jon Scherdin, and Rob Taylor, for assistance and support provided during the development of the DSM-5 Field Trial REDCap System and throughout the DSM-5 Field Trials. The authors would also like to acknowledge the efforts of the temporary research staff (Alison Newcomer, June Kim, and Mellisha McKitty) and research interns in the APA Division of Research and graduate students in the Department of Mental Health at Johns Hopkins Bloomberg School of Public Health (Flora J. Or and Grace P. Lee) for their research support. Last, the authors would like to acknowledge the research coordinators across the DSM-5 Field Trial sites, without whose concerted efforts in learning, implementing, and adhering to the procedures involved in this complex multisite study the field trials would not have been possible.
Research coordinators at the adult field trial sites: Natalie St. Cyr, M.A., Nora Nazarian, and Colin Shinn (The Semel Institute for Neuroscience and Human Behavior, Geffen School of Medicine, University of California Los Angeles, Los Angeles, Calif.); Gloria I. Leo, M.A., Sarah A. McGee Ng, Eleanor J. Liu, Ph.D., Bahar Haji-Khamneh, M.A., Anissa D. Bachan, and Olga Likhodi, M.Sc. (Centre for Addiction and Mental Health, Toronto, Ont., Canada); Jeannie B. Whitman, Ph.D., Sharjeel Farooqui, M.D., Dana Downs, M.S., M.S.W., Julia Smith, Psy.D., Robert Devereaux, Elizabeth Anderson, Carissa Barney, Kun-Ying H. Sung, Solaleh Azimipour, Sunday Adewuyi, and Kristie Cavazos (Dallas VA Medical Center, Dallas, Tex.); Melissa Hernandez, Fermin Alejandro Carrizales, Patrick M. Smith, Nicole B. Watson, M.A., and Martha Dahl (University of Texas San Antonio School of Medicine, San Antonio, Tex.); Kathleen Grout, M.A., Sarah Neely, Lea Kiefer, M.P.H., Jana Tran, M.A., Steve Herrera, and Allison Kalpakci (Michael E. DeBakey VA Medical Center and the Menninger Clinic, Houston, Tex.); Lisa Seymour, Sherrie Hanna, Cynthia Stoppel, Kelly Harper, Scott Feeder, and Katie Mingo (Integrated Mood Clinic & Unit and the Behavioral Medicine Program at Mayo Clinic, Rochester, Minn.); Jordan Coello and Eric Wang (University of Pennsylvania School of Medicine, Philadelphia, Pa.).
Research coordinators at the pediatric field trial sites: Kate Arnow, Stephanie Manasse, and Nandini Datta (Stanford University Child & Adolescent Psychiatry Clinic and the Behavioral Medicine Clinic, Palo Alto, Calif.); Laurie Burnside, M.S.M., C.C.R.C., Darci Anderson, Heather Kennedy, M.P.H., Elizabeth Wallace, Vanessa Waruinge, and Amanda Millar (The Children’s Hospital, Aurora, Colo.); Julie Kingsbury, C.C.R.P., and Brenda Martin (Child Behavioral Health, Baystate Medical Center, Springfield, Mass.); Zvi Shapiro, Julia Carmody, Alex Eve Keller, Sarah Pearlstein Levy, Stephanie Hundt, and Tess Dougherty (New York State Psychiatric Institute at Columbia University, New York, N.Y.; Weill Cornell Department of Psychiatry at Payne Whitney Manhattan Division, New York, N.Y.; North Shore Child and Family Guidance Center, Roslyn Heights, N.Y.; and Weill Cornell Department of Psychiatry at Payne Whitney Westchester Division, White Plains, N.Y.).