In any controlled clinical trial, the validity of the study conclusion is limited by the reliability of the outcomes measured
(1). In studies that use more than one rater, it is critically important that all raters throughout the duration of the study similarly use all rating instruments in a reliable way. For continuous measures such as clinical rating scales, interrater reliability can be measured by calculating intraclass correlation coefficients
(2). Despite the importance of statistically establishing rater reliability, a review of recent literature suggests that this issue is most often ignored
(3).
Problems establishing a pool of reliable raters include the logistical obstacles involved in multicenter trials, which may have as many as 40–50 raters at multiple sites. The initial investigators’ meetings typically do not test reliability among the raters present. To establish reliability, videotapes of actual patients can be mailed to each rater, who would then return both the videotapes and the rating scores to a central coordinator. This is a cumbersome, labor-intensive, and often expensive process. Furthermore, when patients decide that they no longer wish to have their videotaped interviews used for training purposes, it might be difficult to be sure that all videotapes have been returned to ensure privacy.
To address this problem, we have developed a web-based system to train raters in the use of psychiatric scales and to test for interrater reliability within a defined group of raters. The advantage of this system over traditional videotapes is that the video images can be transmitted anywhere electronically without the unwieldy process of sending and receiving videotapes. Furthermore, through interactive technology, the rating scores can be saved online in a centralized database, and interrater reliability can be calculated in real time. This process also minimizes errors due to coding and entry of data from paper-and-pencil entries.
A potential disadvantage of this proposed system is the cost of developing interactive videotapes with actual patients who at any time could withdraw permission to use their interviews. Therefore, we conducted a study to assess the validity of using videotaped interviews of actors portraying depressed patients. Actors simulating patients have been accepted for a variety of training purposes in medical education
(4–
9). However, this practice has not been widely used in psychiatry. Therefore, the actors’ ability to convey both the verbal and subtle nonverbal cues of a person with a psychiatric illness in the course of an interview needs to be demonstrated. This initial study compares the Hamilton Depression Rating Scale (HDRS) scores of experienced raters blindly rating videotapes of actors and actual patients with various levels of depression.
Method
Two patients with major depression (one older man and one younger woman) had been assessed by using an unpublished semistructured interview for the HDRS. These assessments had been videotaped at the initiation of treatment, during treatment, and after successful completion of treatment. Both patients had provided informed consent for the use of their videotapes for research purposes. The six selected interviews illustrated HDRS scores below 10 (an absence of depression), scores of 11–20 (mild to moderate depression), and scores above 21 (severe depression) (
Figure 1). Scripts were generated from these videotapes. In order to create realistic portrayals of different stages of depression, a male actor and a female actor were recruited. These two actors were mental health professionals and had worked for several years with depressed patients. They were trained by viewing the videotaped interviews and by using scripts derived from the interviews. The actors then portrayed the three different HDRS interviews from the same-gender patients. The actors’ portrayals of the interviews were videotaped in the same room and with the same camera as the actual patients’ interviews.
The videotapes of both actors and patients were sent to a collaborating research site at Cornell University to ensure that none of the raters had any prior knowledge of either the actors or the patients. Four experienced HDRS raters at Cornell University with previously established reliability for the HDRS participated in six sessions over 3 weeks. During each session, a rater assessed three videotaped interviews of a single subject (either an actor or a patient) shown without depression, with mild to moderate depression, and with severe depression. The rater was told that the person on the videotape was either a patient or an actor.
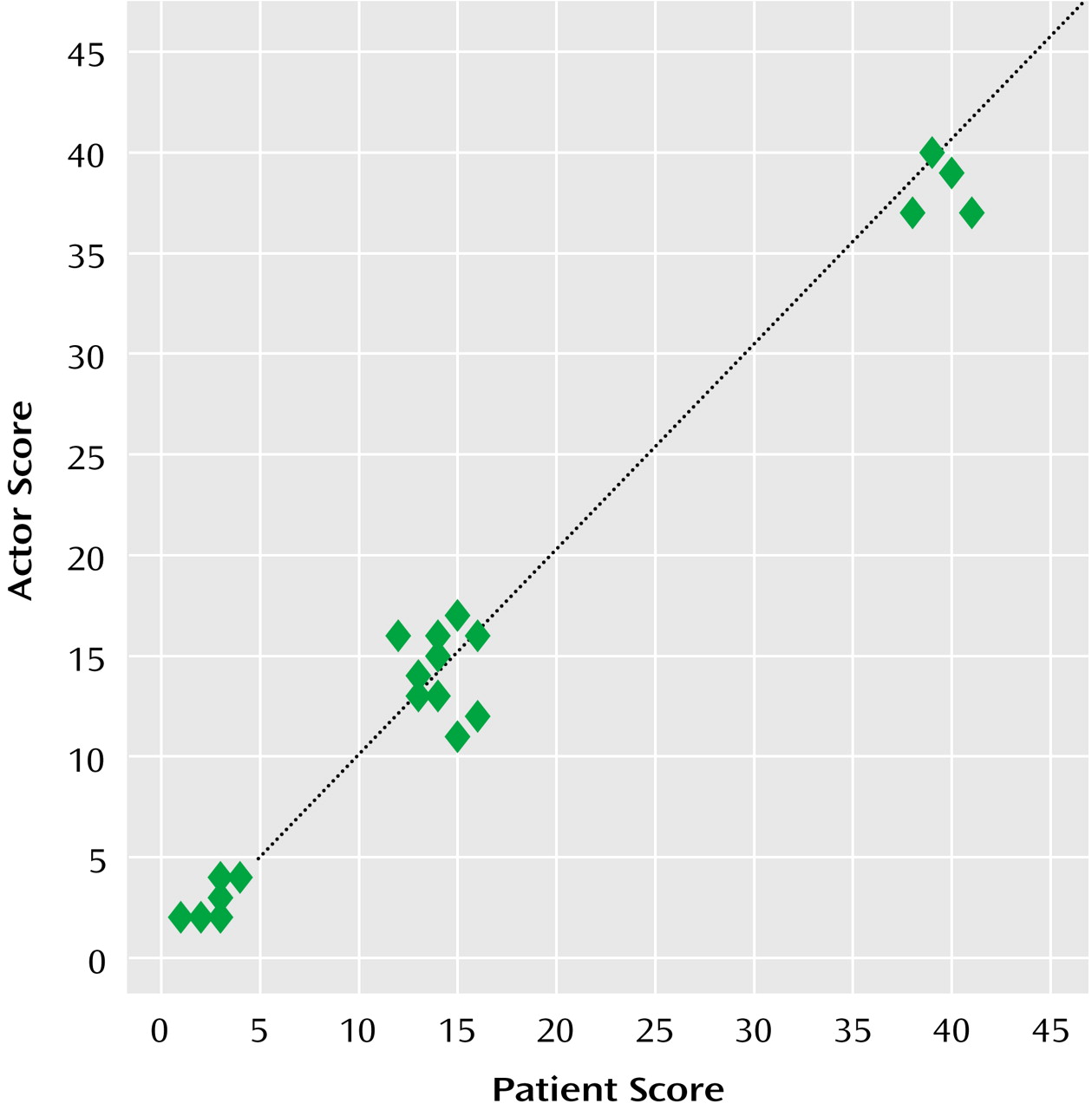
To determine to what extent the raters could distinguish the actors and the patients, they were asked to guess whether they had rated a patient or an actor portraying a patient. They scored their certainty of that guess on a 10-point scale. In addition, the raters were asked their opinion of the quality of the subjects’ (actors’ or patients’) portrayals of depressive psychopathology by answering the following question, “Was this subject presenting in a way that was consistent with a depressed person during a course of depression?” on a scale of 0 (not at all) to 10 (very much). Finally, the raters were asked to complete the HDRS for each interview. Correlations were calculated for the HDRS scores of each actor-patient pair, and intraclass correlation coefficients were calculated for the ratings of both the actors and the patients.
Results
Experienced raters correctly identified actors or patients seven (44%) of 16 times or less than what would be expected by chance (i.e., 50%). When raters guessed incorrectly, they were as certain of their guesses as when they guessed correctly. In terms of “presenting in a way that was consistent with…depression” on a 10-point scale, the mean scores were 7.1 (SD=2.4) for the actors and 6.5 (SD=2.4) for the patients.
The scores generated for the actors’ interviews were highly correlated with the scores generated for the patients’ interviews (r=0.99, p<0.001). Intraclass correlation coefficients calculated with the ratings of the actors and the patients were 0.99 for both groups.
Discussion
These results demonstrate the feasibility of using trained actors to portray depressive psychopathology to establish interrater reliability. Therefore, training and testing materials for raters participating in multicenter clinical trials could be developed by using trained actors without the risk of disseminating the clinical information of actual patients. In this study, the two actors had extensive experience in the field of mental health assessments. This experience probably contributed to a more realistic portrayal of depression. This highlights the importance of selecting and training actors appropriately to ensure an even quality in the portrayal of psychopathology, especially if this method becomes common for use in clinical trials.