Since 2006, genome-wide association studies (GWAS) have identified specific genetic variants underlying a range of common medical disorders. At the same time, these findings have demonstrated that a rate-limiting challenge for successful gene identification is the availability of large populations of case and control subjects. For example, the detection of loci influencing complex disorders such as schizophrenia and diabetes required tens of thousands of such individuals (
1,
2). The evidence thus far suggests that the genetic architecture of psychiatric disorders involves multiple loci of modest effect (
3). Emerging evidence from GWAS of bipolar disorder has been promising (
4), but there is now an urgent need for the collection and genetic analyses of much larger cohorts than have been studied to date in order to identify the common and rare variants that underlie the substantial heritability of bipolar disorder.
The increasing utilization of electronic health records (EHRs) provides new opportunities for epidemiologic and genetic research. A ready repository of clinical and phenotypic data contained in health system EHRs can enable low-cost population-based studies of unprecedented size. A growing number of studies have mined these data for a range of applications, including pharmacovigilance (
5–
8) and genetic association studies (
9–
11). In addition to the use of structured codified data (e.g., diagnostic codes, demographic variables), text mining by natural language processing allows the accrual and analysis of detailed, longitudinal clinical data for research purposes (
12).
Support for the validity of EHR-based diagnosis has emerged from GWAS in which previously established gene associations have been detected in independent samples by using phenotypes derived from EHRs (
11,
13–
15). However, the use of informatics-based phenotyping for psychiatric disorders presents special challenges. Unlike most other classes of medical illness, psychiatric disorders lack established biological markers of diagnosis. Clinical diagnosis in psychiatry relies on constellations of self-reported symptoms and behavioral observation. There is widespread concern that misclassification may occur without extensive, validated diagnostic methods. Given this, the gold standard in clinical, epidemiologic, and genetic studies of psychopathology has been direct assessment by trained observers or clinicians using structured or semistructured diagnostic interviews. However, such methods are costly and labor-intensive. Alternative methods have been validated (e.g., schizophrenia diagnosis based on diagnostic codes in a Swedish Hospital Discharge Registry [
3]), but such methods have not been widely used.
In the present study, we sought to evaluate the validity of EHR-based case and control ascertainment of bipolar disorder. We defined a set of algorithms to extract diagnostic data from the EHRs of a large health care system. The algorithms included one based on natural language processing and several based on coded variables. We assessed the diagnostic validity of each algorithm against the gold standard of in-person semistructured interviews conducted by trained clinical researchers. Here we show that high levels of diagnostic specificity and positive predictive values (PPVs) for bipolar disorder case and control subjects are achievable by means of high-throughput EHR data mining.
Method
This study was conducted as part of the International Cohort Collection for Bipolar Disorder (ICCBD), an international consortium designed to collect a large sample (N=19,000 case and 19,000 control subjects) for genetic studies of bipolar disorder. The Massachusetts General Hospital site of the ICCBD aimed to collect DNA from 4,500 cases and 4,500 controls by linking discarded blood samples to de-identified EHR data.
Data Source and Population
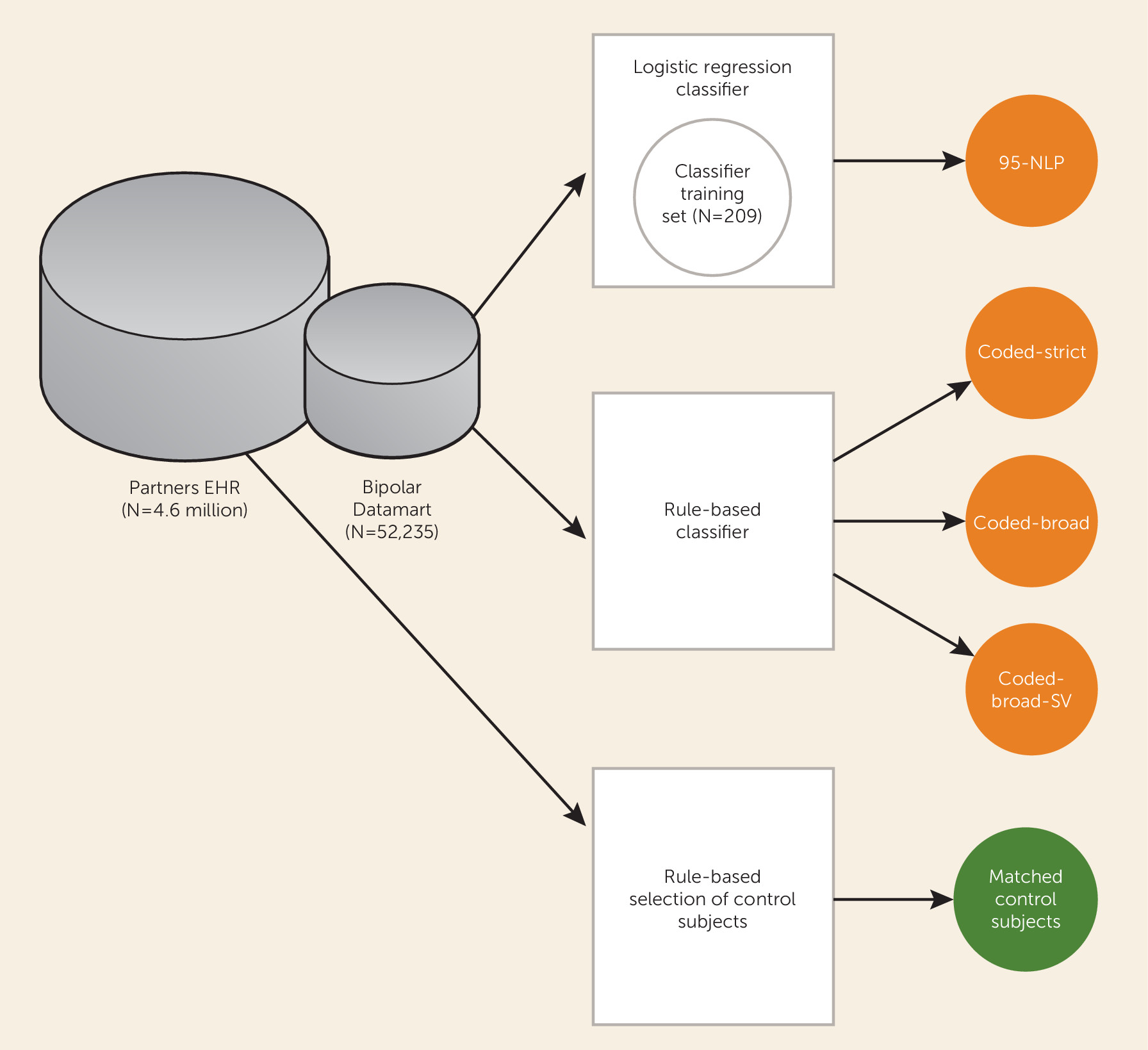
A schematic diagram of the study is presented in
Figure 1. Our primary data source was the Partners Healthcare Research Patient Data Registry, which spans more than 20 years of data from 4.6 million patients. The database contains over 227 million encounters, 193 million ICD-9 diagnoses, 105 million medications, 200 million procedures, 852 million laboratory values, and over 55 million unstructured clinical notes, which are a combination of outpatient visit notes, inpatient discharge summaries, radiology reports, and others. The registry population is approximately 55% female and 72% Caucasian and has an average age of 45.7 years (SD=23.2).
Patients with at least one diagnosis of bipolar disorder (ICD-9 and DSM-IV-TR codes 296.4*–296.8*) or manic disorder (ICD 296.0*–296.1*) in the billing data or outpatient medical records at Massachusetts General Hospital, Brigham and Women’s Hospital, or McLean Hospital were selected for inclusion in a data set, referred to as a “datamart.” The datamart consisted of all electronic records from 52,235 patients analyzed with the Informatics for Integrating Biology and the Bedside (i2b2) Workbench software (i2b2 v1.6.04;
https://www.i2b2.org/software/index.html#) (
16). The i2b2 system is a scalable computational framework for managing health data, and Workbench facilitates data analysis and visualization (
17). Billing code data were available for all public and private payers. Medication data were available from both medications dispensed by an inpatient pharmacy (27%) and medications prescribed in the EHR (73%). The Partners HealthCare System institutional review board approved all aspects of this study.
Clinician Chart Review to Establish Gold Standard
From the bipolar datamart, a random sample of 209 patients with at least one outpatient psychiatric diagnostic evaluation note, inpatient or emergency psychiatric consultation note, or discharge summary from a psychiatric inpatient unit were selected for chart review. Three experienced, board-certified psychiatrists (J.W.S., R.H.P., M.N.V.) reviewed all psychiatric notes in the patient’s record and arrived at a consensus diagnostic status of bipolar disorder, not bipolar disorder, or not enough information. Review guidelines for assigning diagnostic status were adapted from the DSM-IV criteria for bipolar disorder. A confidence level of high, moderate, or low was also assigned to each classification to denote the level of evidence supporting the diagnosis (see Figure S1 in the data supplement accompanying the online version of this article).
Classification Algorithm Using Natural Language Processing
During the chart review, clinicians also identified terms in the narratives that were either consistent or inconsistent with a diagnosis of bipolar disorder (e.g., “increasing racing thoughts” is consistent with bipolar disorder, and “no history of mania” is inconsistent). The instances of related diagnoses, encounters, procedures, and medications from the structured medical record were also identified as consistent or inconsistent with bipolar disorder (the full list of features is available in the Data S1 section of the online
data supplement). These terms were subsequently extracted from each narrative note with natural language processing using the HITEx platform (
18), which identifies terms using regular expressions (flexible matching) and applies negation and context algorithms to filter inappropriate matches. The presence or absence of a term then becomes a feature of each note, which can be used in classification algorithms.
We used the clinician-reviewed classifications to train models to predict the probability of a bipolar diagnosis or no bipolar diagnosis with a confidence level of moderate or high at each visit on the basis of a logistic regression classifier with the adaptive least absolute shrinkage and selection operator (LASSO) procedure. The adaptive LASSO procedure simultaneously identifies important features and provides stable estimates of the model parameters (
19). It is often applied in high-dimensional data sets to select the more useful subset of features for modeling because it shrinks the coefficients of noninformative features (covariates) to zero. The optimal penalty parameter was determined on the basis of the Bayesian information criterion. We first trained a note-level model to predict the probability of bipolar disorder given feature information from each note. Since the amount of diagnostic information contained in an evaluation note could differ substantially from that in a follow-up note, we trained a second logistic regression model using the note-level predicted bipolar disorder probability and the type of clinical note as features. This second model aggregates longitudinal information to classify bipolar disorder at the patient level.
Rule-Based Classification Algorithms for Bipolar Disorder
Because the regression classification algorithm required that patients have electronic psychiatric clinical notes, which were widely adopted only in 2007, we developed additional rule-based classifiers that rely solely on coded diagnostic, encounter, and medication information, which have been recorded uniformly since 1998. Three coded rule-based algorithms—coded-broad, coded-strict, coded-strict-single-visit (coded-strict-SV)—for identifying patients with bipolar disorder were developed on the basis of the patient’s diagnostic and treatment history.
Table 1 outlines the criteria for each rule-based algorithm.
Rule-Based Classification Algorithm for Control Subjects
We identified a cohort of control patients who were at least 30 years old and had no ICD-9 codes or history of medications related to a psychiatric or neurological condition. We selected 1.2 million patients meeting these criteria in the research patient data registry for a control pool. The control patients were then matched 15:1 to the algorithm-classified case patients on the basis of age, gender, race/ethnicity, and health care utilization (number of facts) by using a standard frequency matching approach.
Validation Clinical Study
Bipolar disorder case and control patients identified by the algorithms underwent semistructured diagnostic interviews using the Structured Clinical Interview for DSM-IV (SCID-IV) by an experienced doctoral-level clinician blinded to the classifier diagnosis and method of selecting the cohort. Interviewers were required to undergo formal SCID training (as recommended at
www.SCID4.org), which was documented for each interviewer. This included careful review of the SCID User’s Guide, instructions, and interview; viewing seven SCID training DVDs; and documenting concordant diagnoses with two SCID training interviews.
Individuals selected by the classification algorithms were invited by mail to participate in the in-person validation study. Subjects were ascertained by a hierarchical application of the algorithms such that they were selected on the basis of the most stringent algorithm for which they met the case definition (95-NLP > coded-strict > coded-broad > coded-broad-SV). The SCID assessment was completed by 190 patients, including 45 patients selected by the 95-NLP probabilistic algorithm; 59 selected by the coded-strict, 31 by the coded-broad, and eight by the coded-broad-SV algorithms; and 20 matched control subjects. To further preserve clinician blinding, we also recruited 27 individuals from advertisements in community clinics at Massachusetts General Hospital who reported a previous diagnosis of schizophrenia or major depression, two disorders commonly considered in the differential diagnosis of bipolar disorder.
Extraction of Subphenotypes
For cases, we aimed to classify relevant subphenotypes associated with bipolar disorder: age at bipolar disorder onset, bipolar disorder subtype, family history of bipolar disorder, and history of: alcohol dependence, drug dependence, suicide attempt, psychosis, or panic disorder/agoraphobia. Two board-certified psychiatrists (J.W.S., R.H.P.) manually reviewed 620 notes to identify important terms (features) indicative of each subphenotype. Each feature was extracted from the notes by using the HITEx system (
18). The gold standard subphenotype classification was based on results of the SCID direct interview and was used to train algorithms using the extracted features. All case patients were used in the training phase regardless of whether they received a SCID diagnosis of bipolar disorder. We trained a separate model for each subphenotype by using the LASSO regression procedure with 10-fold cross-validation. There were two exceptions to the above procedure. Age at onset was categorized into early onset (age <18), typical onset (age 18–40), and late onset (age >40); bipolar subtype was categorized into bipolar disorder I, bipolar disorder II, other bipolar disorder, and schizoaffective disorder, bipolar type. To validate the categorization of these two subphenotypes, the research coordinator reviewed text from 701 notes that included explicit mention of bipolar disorder subtype or age at onset and assigned the appropriate category.
Statistical Analysis for Validation Study
For the algorithm using natural language processing, performance of the logistic regression model was assessed by using receiver operating curve (ROC) analysis for models in which specificity was set at the desired threshold of 95%. The overall performance of this algorithm, referred to as 95-NLP, was summarized by using the area under the ROC curve (AUC). Performance of the case and control classification compared with the in-person validation study was assessed by using the PPV for the algorithm classification relative to the SCID classification. The PPV for cases was calculated as the proportion of cases diagnosed as bipolar (bipolar I, bipolar II, other bipolar, or schizoaffective disorder, bipolar type) by SCID interview given an algorithm diagnosis of bipolar disorder. This PPV is based on a base population defined by inclusion in the bipolar datamart (i.e., having at least one billing code for bipolar disorder or manic disorder). Because cases selected by one algorithm (e.g., 95-NLP) might also be classifiable by another algorithm (e.g., coded-strict), we also calculated the PPV by allowing each case to be included for any algorithm capable of classifying the case. For example, if a subject was ascertained with the 95-NLP algorithm but also met the criteria for bipolar disorder according to the coded-strict and coded-broad rules, she would be included in calculations of PPV for all three definitions. This “nonhierarchical” PPV provides an estimate of the diagnostic performance of each algorithm regardless of the algorithm by which subjects were ascertained. The PPV for control subjects represents the proportion of individuals classified as control subjects (no bipolar disorder diagnosis) by SCID interview given an algorithm classification as a control. For subphenotype assessment, PPVs were calculated against the SCID interview gold standard.
Results
After manual review of 612 notes from the 209 randomly selected patients in the bipolar datamart, 132 patients were classified as “bipolar” (37% with high confidence, 26% with moderate confidence, 37% with low confidence), 69 were classified as “not bipolar” (36% with high, 35% with moderate, and 29% with low confidence), and eight were classified as “insufficient information.” We identified 401 terms relevant to bipolar disorder to be used as features in the model training. An additional 13 relevant coded terms from the EHR, such as those relating to sex and past prescription of lithium, were also included as features.
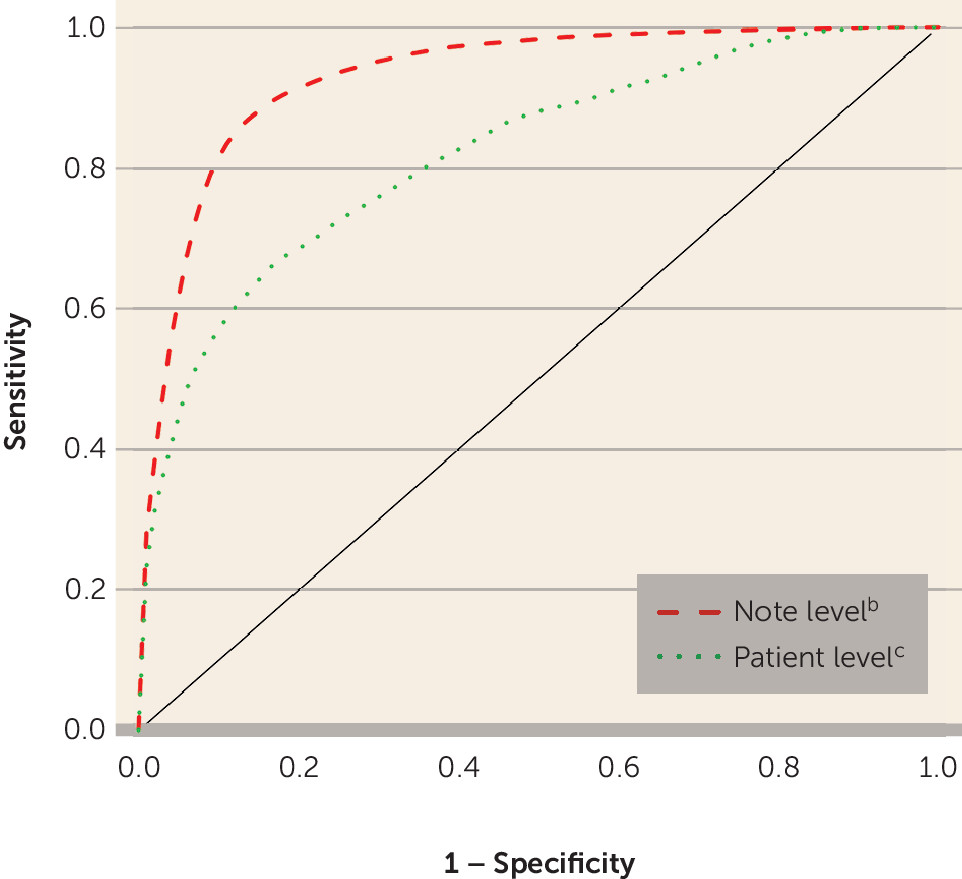
Of the 414 features identified for model training, the adaptive LASSO selected 13 features for bipolar disorder classification (
Table 2). The final model for classifying each note as indicating a bipolar disorder diagnosis yielded an AUC of 0.93 (SE=0.01), with a sensitivity of 0.53 when the specificity was set at 0.95 (
Figure 2). The AUC for classifying an individual as having bipolar disorder or not across notes and other longitudinal data was 0.82 (SE=0.03). After running the logistic regression classifier on datamart patients with sufficient clinical narratives, an initial set of 1,776 patients were selected as having bipolar disorder. Patients in the datamart not classified by the probabilistic algorithm were eligible for classification by the rule-based algorithms. In this process, 11,492 patients were selected by the coded-strict algorithm, 3,381 by the coded-broad algorithm, and 5,220 by the coded-broad-SV algorithm, and 296,356 control subjects with no psychiatric or neurologic disorders were matched to the case subjects (
Table 3).
According to the SCID gold standard, the cases selected by 95-NLP yielded a PPV of 0.85 (95% confidence interval [CI]: 0.72–0.93) (
Table 4). The coded algorithms resulted in PPVs of 0.79 (95% CI: 0.67–0.87) for cases selected by the coded-strict algorithm, 0.62 (95% CI: 0.43–0.78) for coded-broad, and 0.50 (95% CI: 0.22–0.78) for coded-broad-SV. No patients selected by the control rules were given a SCID diagnosis of bipolar disorder (PPV: 1.00, 95% CI: 0.84–1.00). As shown at the bottom of
Table 4, when results were calculated on the basis of nonhierarchical rules (that is, classifying subjects according to all rules for which they met criteria), the PPVs for the coded-strict and coded-broad algorithms increased substantially.
Table 5 provides positive and negative predictive values for each of the eight relevant subphenotype algorithms. Applying these algorithms to the selected bipolar disorder cases, we identified a history of alcohol abuse in 54% of the patients, a history of substance abuse in 40%, a history of psychosis in 35%, a past suicide attempt in 10%, and a history of panic disorder in 42%. In addition, 75% of the case subjects were identified as having bipolar I disorder, and 35% of the case subjects had an identified family history of bipolar disorder. Where the age at onset was known, 46% of patients were identified as having an early onset (age <18) and 10% as having a late onset (age >40).
Discussion
Clinical characterization in psychiatric research has traditionally been an expensive and labor-intensive proposition involving lengthy diagnostic interviews. The expanding availability of EHRs offers a new and powerful alternative for the collection of diagnostic and outcome data. In the realm of genetic research, the accrual of large samples of case and control subjects has become a rate-limiting challenge for the discovery of risk variants. Prior studies by our group and others have supported the validity of EHR-based phenotyping by replicating genetic and epidemiologic findings by means of these methods (
10,
11,
15). We have also previously demonstrated the utility of longitudinal EHR phenotyping for pharmacovigilance, neuroimaging, and treatment outcome research (
5,
6,
20–
22). However, the present study provides direct validation of informatic-based ascertainment by comparing diagnoses derived from EHRs to a gold standard of traditional clinician-based interviews.
Several findings of this study warrant highlighting. First, we found that text mining of medical records using natural language processing can be used to develop highly specific and predictive diagnostic algorithms that are comparable to those achieved by direct interview. In the model-training phase, we derived an algorithm using natural language processing that had 95% specificity and high predictive validity (AUC=0.82) compared with expert clinician-derived diagnoses of bipolar disorder by manual chart review. In the direct-interview validation phase, our natural language processing algorithm demonstrated high predictive validity compared with blinded semistructured clinical interviews (PPV=0.85). This degree of diagnostic accuracy is particularly notable in the context of the interrater reliability of standard diagnostic interviews themselves. For example, the DSM-5 field trials had a pooled kappa of only 0.56 for bipolar I disorder when patients were evaluated by two independent clinicians within 2 weeks of each other (
23) (studies using earlier diagnostic criteria achieved higher though still imperfect reliability estimates [
24,
25]). Thus, some degree of diagnostic imprecision is expected and likely unavoidable.
We also obtained excellent PPVs for certain algorithms based on coded EHR data. The coded-strict algorithm, which required a history of multiple bipolar disorder diagnoses and either treatment at a bipolar disorder specialty clinic or prescription of lithium or valproate, achieved a PPV of 0.79 (rising to 0.84 when nonhierarchical rules were used). In addition, our diagnostic rule for ascertainment of control subjects, comprising multiple filters to exclude psychopathology, yielded a PPV of 1.0.
Less robust performance was seen for the remaining diagnostic rules, which relied on a broader set of criteria. The coded-broad definition required at least two bipolar disorder diagnoses, a predominance of bipolar disorder diagnoses over diagnoses of other psychotic disorders or depression, and treatment with lithium, valproate, or antipsychotic medication. The PPV for this definition was 0.62 but rose to 0.80 when the nonhierarchical classification was used. The coded-broad-SV definition was identical except that the coded bipolar disorder diagnoses could have been given less than 1 month apart. It is noteworthy that these criteria are still more stringent than those often used in population-based studies that rely on claims data in which one or two instances of a diagnostic code are used to define cases. Indeed, our results suggest that studies relying on such claims-based criteria are likely to include a substantial proportion of false positives. The prospective, longitudinal nature of EHRs also provides a critical advantage for diagnosis. For example, longitudinal studies indicate that as many as 15% of bipolar cases are later diagnosed as schizophrenia or schizoaffective disorder (
26,
27) and nearly 40% of individuals with psychotic depression later receive a non-mood-disorder diagnosis (
28). Thus, claims-based studies that rely on the presence of a single diagnostic code may result in substantial misclassification.
We also examined the reliability of several subphenotypes and comorbidities that are relevant for genetic subtyping. The PPV statistics comparing informatic-based diagnosis to diagnostic interview demonstrate that such finer-grained phenotyping by EHR-based algorithms is a viable approach. However, ambiguous information for some of these phenotypes (e.g., a lack of an affirmative statement or negation in the record) meant that we were unable to classify a portion of cases with respect to these subphenotypes.
Our high-throughput informatics-based phenotyping approach was designed to allow the rapid accrual of diagnostic data and blood samples for genetic analysis. We used these definitions to ascertain case and control subjects for the ICCBD consortium by linking phenotypic data to discarded blood samples as previously described (
11). In brief, case and control medical record numbers are submitted to the Partners HealthCare Crimson system, which allows prospective collection of discarded samples. Acting as an “honest broker,” Crimson matches deidentified phenotypic data to discarded blood samples. Using the case/control definitions described in this study, we collected approximately 4,500 subjects with bipolar disorder and 5,000 control subjects over 3 years. The control blood samples were collected in 10 weeks. Prior simulations have demonstrated that EHR-based ascertainment and sample collection for genetic studies using the i2b2 system provide an approximate 10-fold reduction in cost compared with standard methods (
29). In sum, the framework we have validated here provides a high-throughput and cost-effective engine for genetic discovery that is exportable to other health care systems (
30).
There are several limitations of our study. First, the precision of our PPV estimates is limited by the sample size. In particular, we had difficulty recruiting subjects who fell into the coded-broad-SV category, and the 95% CI around our point estimate for PPV is correspondingly broad. Recruitment of these subjects was undoubtedly more difficult because of the nature of the phenotype definition. Specifically, while these participants received more than one bipolar disorder diagnosis, the diagnoses occurred during a single episode of inpatient or outpatient care. This likely captured individuals who are no longer in the health care system and were thus more likely to be lost to follow-up. Second, the applicability of our methods to other health care systems may vary depending on informatics infrastructure. Fortunately, EHR mining is increasingly widespread, including through the growing network of systems that have adopted the i2b2 platform (
12,
31). Second, we included cases of bipolar disorder not otherwise specified in our definition of bipolar disorder cases, although some genetic studies have excluded such cases. However, such cases have been included in numerous recent large-scale bipolar disorder GWAS (e.g., those described in references
4 and
32). Classifying these cases as indeterminate has a negligible effect on the PPVs shown in
Table 4, reducing them by 0%−3%.
In sum, our results support the validity and utility of informatic-based phenotyping for psychiatric research. It is important that the EHR ascertainment of bipolar disorder case and control subjects was highly concordant with the gold standard of in-person diagnostic interviews. The best-performing case definition algorithm made use of natural language processing, but we demonstrated that, when guided by clinical expertise, algorithms that extract coded EHR data can also yield valid phenotypes. In addition to being used on their own, EHR algorithms could be useful as a preliminary screening step to ascertain an “enriched” set of case or control subjects followed by more traditional direct interview phenotyping. With the increasingly widespread implementation of EHRs, this study supports the application of high-throughput in silico phenotyping for epidemiologic, genetic, and clinical research.
Acknowledgments
The authors thank April M. Hirschberg, M.D., Curtis Wittman, M.D., Stephanie McMurrich, Ph.D., and Jamie Dupuy, M.D., who served as clinician interviewers.
Members of the International Cohort Collection for Bipolar Disorder (ICCBD) are Jordan W. Smoller (principal investigator); Roy H. Perlis, Phil Hyoun Lee, Victor M. Castro, and Alison G. Hoffnagle (Massachusetts General Hospital); Pamela Sklar (principal investigator), Eli A. Stahl, Shaun M. Purcell, Douglas M. Ruderfer, Alexander W. Charney, and Panos Roussos (Icahn School of Medicine at Mount Sinai); Carlos Pato, Michele Pato, Helen Medeiros, and Janet Sobel (University of Southern California); Nick Craddock, Ian Jones, Liz Forty, Arianna DiFlorio, and Elaine Green (Cardiff University); Lisa Jones and Katherine Dunjewski (Birmingham University); Mikael Landén, Christina Hultman, Anders Juréus, Sarah Bergen, and Oscar Svantesson (Karolinska Institutet); and Steven McCarroll, Jennifer Moran, Jordan W. Smoller, Kimberly Chambert, and Richard A. Belliveau, Jr. (Stanley Center for Psychiatric Research, Broad Institute).