Large randomized, controlled trials are considered the gold standard for the evaluation of preventive or therapeutic interventions. However, often it is practically feasible to perform only relatively small randomized controlled trials. Several investigators have addressed whether the results of large trials agree with the results of smaller trials and meta-analyses thereof on the same topic. Villar et al.
(1) reported moderate agreement between meta-analyses of small trials and large trials. Cappelleri et al.
(2) concluded that the two methods usually agree. Conversely, LeLorier et al.
(3) concluded that meta-analyses of small trials fail to predict the results of subsequent large trials in one-third of cases. A systematic comparison of all of these empirical assessments
(4,
5) concluded that disagreements may be less prominent for primary outcomes and that, overall, the frequency of significant disagreements beyond chance is 10%–23%.
Prior investigations in the comparison of large versus smaller trials have typically not targeted mental health-related interventions. The vast majority of randomized controlled trials in mental health are of small sample size. It is important to understand how reliable these results are and whether we should expect large trials to confirm or to refute results from small trials. Moreover, the conduction of randomized controlled trials for mental health interventions may have peculiarities in terms of types of interventions, subject recruitment, and selected outcomes. Thus, we decided to evaluate the comparative results of large and smaller randomized controlled trials on mental health-related interventions across a variety of topics.
Discussion
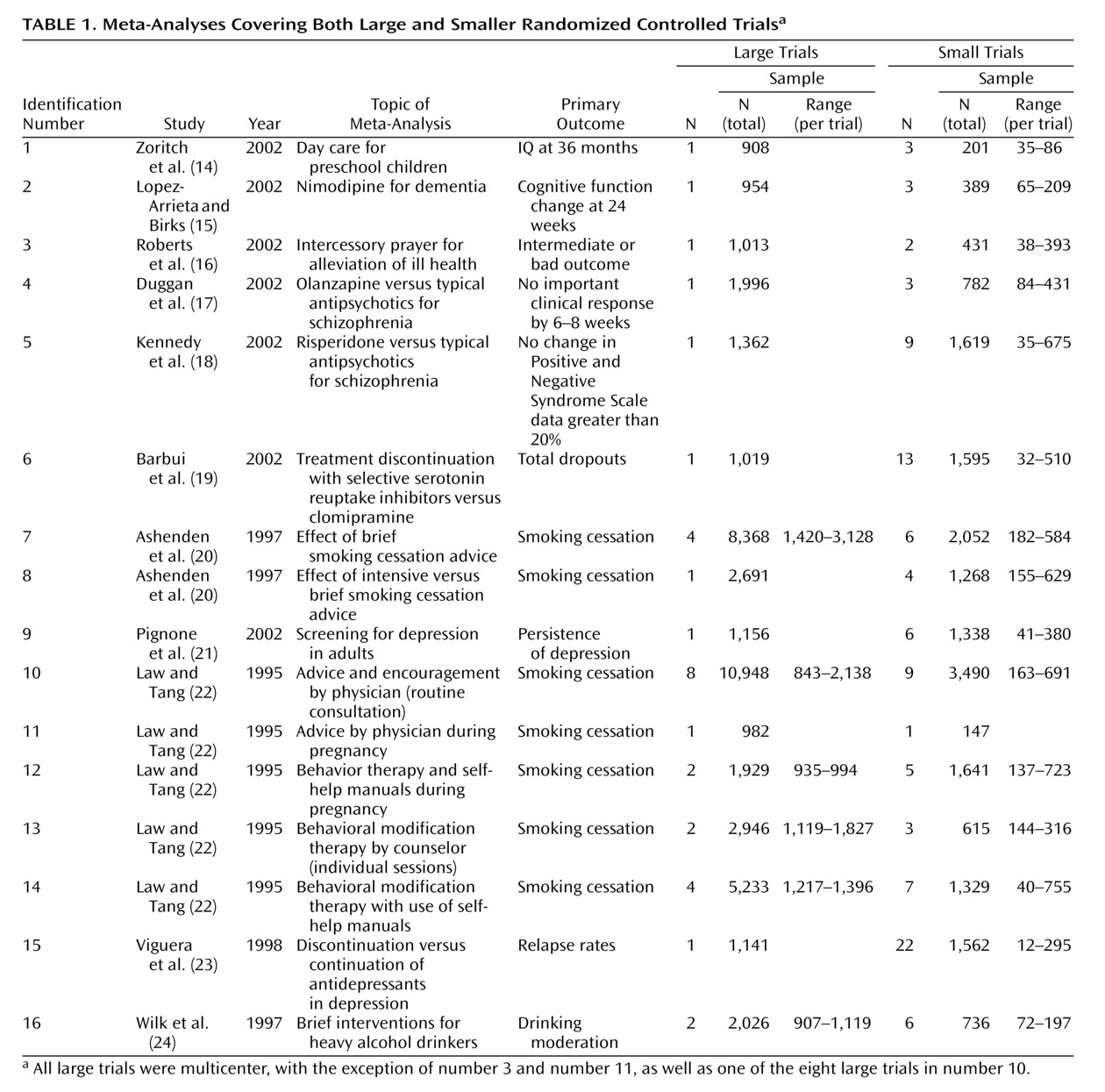
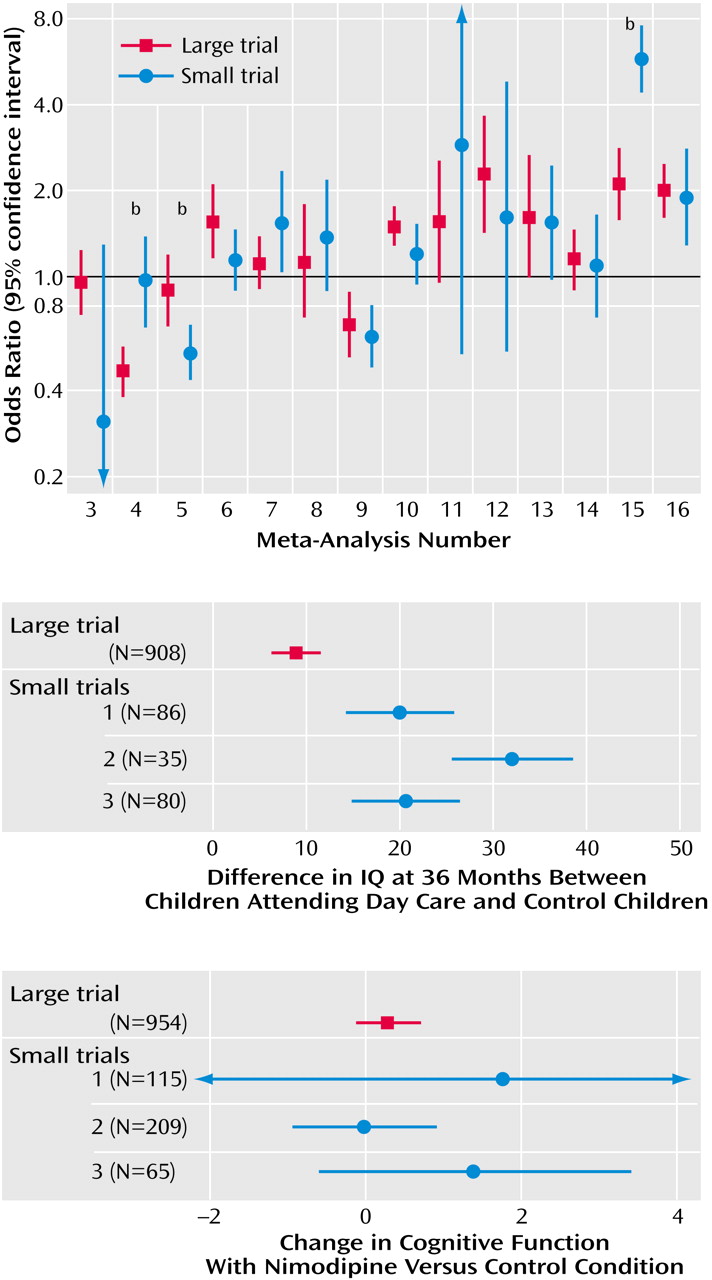
Our empirical data suggest that in the field of mental health, evidence from small trials is usually not incompatible with the results obtained from large trials on the same question. Nevertheless, in one of four cases, we observed discrepancies beyond chance in the results of large versus smaller trials. Frequently, the effect size was much different in absolute magnitude in large versus smaller trials. In most but not all discrepancies, the large trials tended to give more conservative impressions about the intervention (or the newer intervention, when interventions were compared), whereas the smaller results conveyed a more enthusiastic picture.
Our findings are in line with previous research comparing meta-analyses of large versus smaller trials in other fields, such as perinatal medicine, cardiology, infectious diseases, surgery, and oncology
(1–
5). In these fields, discrepancies beyond chance were noted in 10% to 23% of cases by random-effects calculations
(1–
5). The 25% disagreement rate that we observed in mental health is compatible with these figures. Fixed-effects estimates of discrepancies tend to be higher, and our current estimate of 31% is also compatible with previous investigations in other fields
(1–
5). We should caution that seven of the 16 meta-analyses that we addressed dealt with smoking cessation, a topic that some investigators may not consider as pertaining to the mainstream of mental health. We believe that the inclusion of these meta-analyses was warranted, given the major importance of the psychological dependence and the strong mental dimension in the establishment of the smoking epidemic. However, exclusion of these meta-analyses would increase the rate of disagreements in our series to 44% (four of nine). Therefore due caution is probably needed on interpreting the results of small trials on mental health interventions.
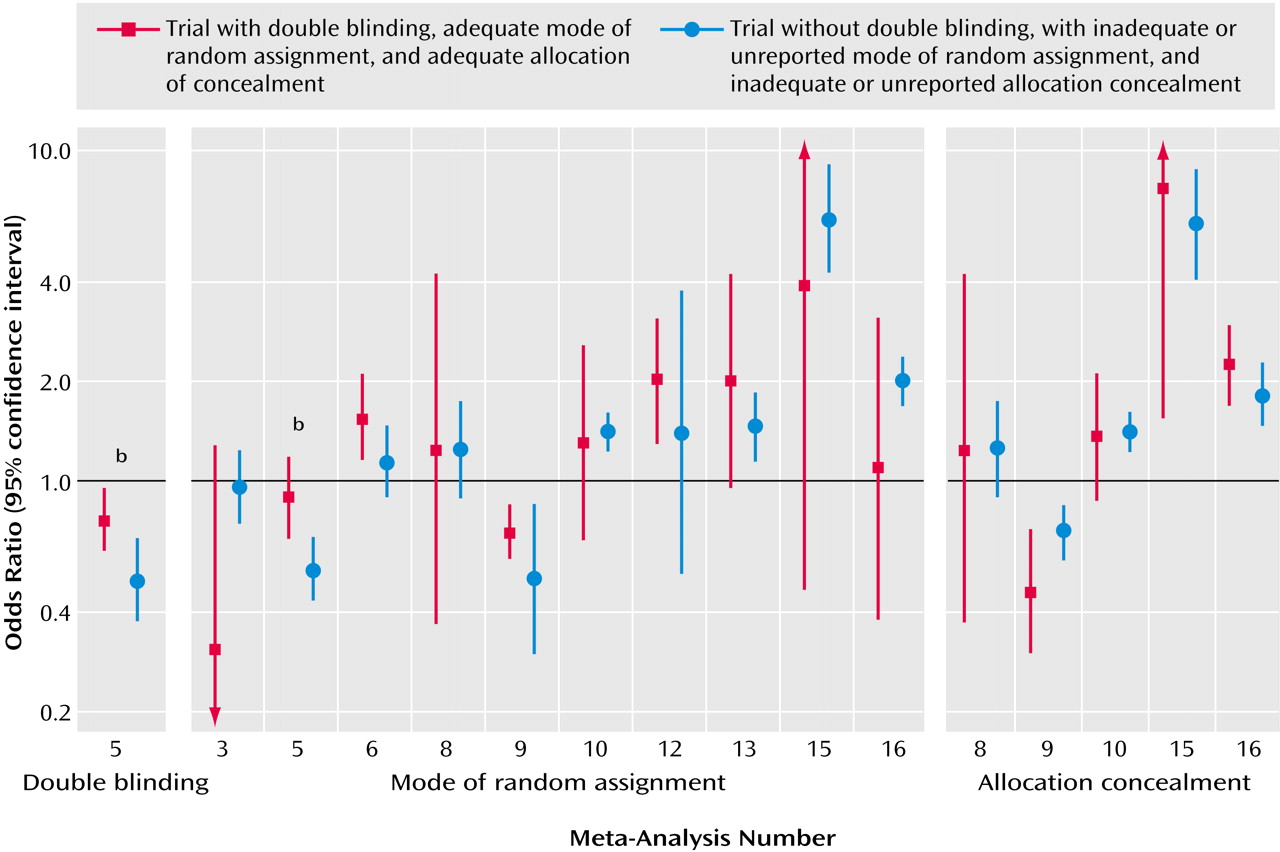
Empirical investigations from other medical fields suggested that variability in the treatment effects of trials may reflect quality differences. In particular, it was claimed that double-blind, adequately randomized, and adequately concealed trials may show more conservative effects for the experimental treatments, compared with trials not meeting or not stating such quality items
(7,
8). However, recent work
(31) has not shown any consistent dependence between these quality items and effect size. Our appraisal of these quality items in mental-health-related trials showed that the differences between “good” and “poor” reported quality trials were also not consistent. In two meta-analyses, the single large trial was also the only one to meet some of these quality aspects, so it is unknown whether differences in effect sizes were due to sample size or the quality of the trial design. Unmasked trials gave more conservative results than double-blind trials in the case of risperidone, but this was an isolated observation. Moreover, it is unknown whether the lack of reporting of specific quality items means that a trial is of poor quality or simply poorly reported
(32). The advent of the Consolidated Standards of Reporting Trials guidelines
(33) should help standardize the reporting of trials across medical fields. This is particularly important for mental health, where our study showed that few trials report an adequate mode of random assignment and allocation concealment. Poor reporting makes difficult the overall assessment of the randomized literature in mental health.
When small and large trials disagree, it is unknown whether the larger trials should be considered to be more reliable. There are several other considerations beyond trial quality. Small trials have large standard errors by definition. With multiple studies addressing the same research question, the most extreme effect sizes may occur with the smallest sample size. In the presence of some publication bias
(34), the largest effect sizes may be seen with the smallest trials. Conversely, large multisite trials are actually summaries of many small trials (the different sites involved) with relative disregard for the potential disagreements between the results observed at different sites. Many of the smaller studies may also be conducted at several clinical sites. In some cases, large and smaller trials may be targeting different patient populations with variable background risks
(35). For various mental-health-related interventions, large trials may be less selective, whereas small trials target patients who have the highest likelihood of response. Thus, in cases of disagreement, small and large trials should be carefully scrutinized for hints to important sources of latent diversity
(36). Discrepancies may be due to more than one cause in each case. For example, in the case of risperidone versus haloperidol, an updated review
(18) contains a number of small trials with “negative” results that had previously remained unpublished. Moreover, these trials differed in the dose of haloperidol. Thus, the original discrepancy may be explained by a combination of publication bias and different design in small versus larger trials. Detection of such sources of heterogeneity may give us important hints about the overall integrity and validity of clinical research in mental health
(37,
38).
We should acknowledge that the definition of “large” trial is unavoidably arbitrary. Moreover, we could identify only 16 meta-analyses in which both large and smaller trials were available, despite the fact that we searched more than 400 systematic reviews. The dearth of meta-analyses with large trials reflects mostly the fact that few such large trials are conducted in the field of mental health. In a recent evaluation of schizophrenia trials, only 2% of 2,000 studies had a sample size exceeding 400 patients
(39). The performance of large trials should be encouraged in the broader mental health field
(40). Nevertheless, large trials will never be performed for most clinical questions because of limitations in resources. For behavioral and psychosocial interventions, standardization of interventions across multiple therapists is difficult. Moreover, even small trials may provide evidence conclusive enough for practical purposes. Additional large trials may be deemed unnecessary or even unethical if small studies have shown a large treatment effect. Therefore, evidence-based medicine will often have to depend on the results of small trials and meta-analyses thereof. Attention to the design, conduct, analysis, and reporting of all trials, regardless of sample size, is thus important, and all trials should be examined as forming a continuum of evidence.